魔域兄弟来战,魔域口袋版楚汉军团战隆重打响 830.26M2024-01-23
玩耍时间到,《蛋仔派对》和《玩具总动员》联动来袭 753.89M2024-01-24
包罗万象,《天启行动》第一个重大版本更新9月29日来袭 198.59M2024-01-25
《反恐行动》共邀国庆封神开榜,版本爽拿200卷轴 623.83M2024-02-01
弹性提前退休 何时能领养老金?北京人社部门回应 76M2024-02-21
我的世界续作什么时候出 公测上线时间预告 193.54M2024-04-07
☘️人心挺好☘️爱游戏app最新官网登录APP下载【首存送彩金☘️💰】🔥支持:64/128bit🔥系统类型:爱游戏app最新官网登录官方网站-App下载(2024全站)最新版本IOS/安卓通用版V.2.9.7.4支持winall/win7/win10/win11🎁☘️安全平台☘️【下载次数685485】APP,现在下载,新用户还送新人礼包是一款能让中华文明传承中医焕发新活力的医疗app,功能简单实用,可以随时随地在手机上学习,还有各种疑难杂症,很容易掌握解题知识。是中医医生、学生、爱好者必备的权威学习工具,严格选择权威数据,全面整理汇编中医经典书籍、医案、方剂。
⚡️☘️⚡️①通过浏览器下载
打开“爱游戏app最新官网登录”手机浏览器(例如百度浏览器)。在搜索框中输入您想要下载的应用的全名,点击下载链接【mobile.centuple.com.cn】网址,下载完成后点击“允许安装”。
⚡️☘️⚡️②使用自带的软件商店
打开“爱游戏app最新官网登录”的手机自带的“软件商店”(也叫应用商店)。在推荐中选择您想要下载的软件,或者使用搜索功能找到您需要的应用。点击“安装”即可开始下载和安装。
⚡️☘️⚡️③使用下载资源
有时您可以从“爱游戏app最新官网登录”其他人那里获取已经下载好的应用资源。使用类似百度网盘的工具下载资源。下载完成后,进行安全扫描以确保没有携带不安全病毒,然后点击安装。
🥔百度百科🥔【爱游戏app最新官网登录】⚡️☁️️⚡️支持:32/64bit⚡️系统类型:爱游戏app最新官网登录(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《爱游戏app最新官网登录》是一款非常好用的漫画阅读软件,里面有很多资源可供您选择哦。
📹恭喜发财大哥们📹【爱游戏app最新官网登录】⚡️🚡⚡️支持:32/64bit⚡️系统类型:爱游戏app最新官网登录(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《爱游戏app最新官网登录》是一款专门针对学习和考试的辅导软件。快对答案下载安装后,用户可以在该应用中选择各类题目进行练习,或者参加其他用户或组织发起的考试,比较自己的答题成绩。此外,该应用内置智能批改功能,可即时分析题目及用户的答题情况,给出针对性的学习建议。总之,快对答案app一款非常实用的学习和考试辅助软件,可以帮助用户更好地提高学习效率!有需要就快来免费下载安装2023快对答案app最新版体验吧!
🛷解答🛷【爱游戏app最新官网登录】⚡️☀️️⚡️支持:32/64bit⚡️系统类型:爱游戏app最新官网登录(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《爱游戏app最新官网登录》是一款资源非常丰富的小说阅读软件,有超多的优质小说等着你来阅读哦。
🎼「百科/秒懂百科」🎼【爱游戏app最新官网登录】⚡️🗺️⚡️支持:32/64bit⚡️系统类型:爱游戏app最新官网登录(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《爱游戏app最新官网登录》是一款非常好用的小说阅读软件,用户提供最舒适的阅读体验。
🛸「解答」🛸【爱游戏app最新官网登录】⚡️♌️️️⚡️支持:32/64bit⚡️系统类型:爱游戏app最新官网登录(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《爱游戏app最新官网登录》是关注体育与健康的关系,用户可以在这里了解如何通过运动保持健康。平台提供丰富的健康资讯和运动建议,帮助用户制定科学的运动计划。平台还介绍了运动营养、康复训练等方面的内容,帮助用户全面提升健康水平,享受健康的生活方式。
⛽️【恭喜发财大哥们】🥇⛽️【爱游戏app最新官网登录】⚡️🎋️⚡️支持:32/64bit⚡️系统类型:爱游戏app最新官网登录(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《爱游戏app最新官网登录》是一款以趣味走路为主旨的app,让大家的运动中寻找乐趣,为全民健康负责,倡导全民运动的健康软件
📡恭喜发财大哥们📡【爱游戏app最新官网登录】⚡️🍶⚡️支持:32/64bit⚡️系统类型:爱游戏app最新官网登录(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《爱游戏app最新官网登录》是是一款体育竞猜互动平台,让用户参与到比赛中,增加更多的乐趣。用户可以在平台上参与各种体育竞猜活动,预测比赛结果、比分等,赢取丰厚奖品。同时,平台还提供专业的分析和数据支持,帮助用户做出更准确的预测,提升竞猜体验。
☕【MBAChina】☕【爱游戏app最新官网登录】⚡️🥎⚡️支持:32/64bit⚡️系统类型:爱游戏app最新官网登录(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《爱游戏app最新官网登录》是一款非常实用的手机直播应用软件,是您手机直播的好帮手。
Ⓜ安全下载Ⓜ【爱游戏app最新官网登录】⚡️🛴️⚡️支持:32/64bit⚡️系统类型:爱游戏app最新官网登录(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《爱游戏app最新官网登录》是一款高额度、低息费、无担保的信用贷款产品。凭身份证即可申请,简单三步操作,即可享受宜享花专属额度。快速贷款,实时审批,快速到帐,循环额度,一次申请,循环使用,持牌借贷平台,科技护航,实力雄厚。
1.🌏了解游戏规则:在登录爱游戏app最新官网登录应用程序之前,务必熟稔各类棋牌游戏之规则,例如斗地主、麻将以及德州扑克等。各款游戏皆具备其特定的玩法及策略,仅用深度理解规则方可在游戏中展现出色表现。可通过查阅专业文献、观看教学视频或与高手展开互动以提升自身的游戏素养。掌控规则乃迈向棋牌大师之路的关键步骤。
2.🕕选择适合自己的游戏:爱游戏app最新官网登录囊括众多棋牌种类,诸如斗地主、德州扑克以及象棋等等,每款游戏独具特色且具备挑战性。在选择游戏中,需根据个人喜好与实际水平做出决策,避免盲目追随热门项目。新手上路不妨先从简易游戏着手锻炼,待技术日臻完善后,逐步挑战更高级别游戏,以适应各类复杂挑战。
3.🚍合理利用道具:在爱游戏app最新官网登录应用平台上,各类道具频繁现身,例如,记牌仪、加倍卡及换牌符号等。这些装备能助玩家于游戏中获胜,然而,若使用失当,反而可能引发不利因素。故而,对待道具的使用须审慎思考,根据实际情况选择合适的使用时机与情境。适时运用恰当的道具,有助于提高效率,使玩家赢得更迅速。
4.🚂与他人交流互动:除自行训练外,在爱游戏app最新官网登录上,用户有机会参与互动交流,进社区、邀好友,甚至参与线上赛,认识更多棋艺爱好者分享经验,从中汲取新知识补足自身不足。因此,与他人的沟通互动在提高棋艺方面发挥着不可忽视的作用。
【河南工会推出首位AI理论宣讲员“豫小宣”******
中工网讯 (工人日报-中工网记者余嘉熙 通讯员王佳宁)近日,河南工会首位AI理论宣讲员“豫小宣”亮相,其身着蓝色工装、语态生动鲜活,在不同场景进行理论宣传、政策解读,构建起全媒体、交互式传播场景,有效提升理论宣讲的感染力和亲和力,让党的创新理论在广大职工群众心中落地生根。
“豫小宣”是基于生成式人工智能技术打造的工会数字人,以AI策划、设计的全新虚拟形象亮相,相较于传统的真人建模数字人,不仅在内容生成速度、灵活性、可持续性、可扩展性等多个维度上展现出显著优势,而且能够迅速响应信息更新,以高效、精准、生动的方式进行宣讲,成为连接工会与职工群众的智能桥梁。
据介绍,“豫小宣”将与河南工会理论宣讲团成员一起进机关、进企业、进社区、进学校、进网络,通过视频、人机对话等新模式,宣讲党的创新理论,讲好新时代劳模故事、劳动故事、工匠故事,增强理论宣讲的吸引力。
为推动新时代工会理论宣讲工作数智化发展,近年来,河南省各级工会坚持“大宣传大宣讲”工作理念,高位推动、创新载体、整合资源,以“中国梦·劳动美”为主线,组织开展多类主题的线上线下宣传教育活动,通过冒热气、接地气、聚人气的宣讲形式,常态化宣讲、专业化领讲、品牌化推广,把党的创新理论送到职工群众心坎里。同时,注重发挥劳动模范、道德模范、大国工匠、最美职工等主体作用,利用云直播、云课堂、AI宣讲等形式,打通线上宣讲渠道,构筑从身边到“指尖”的立体宣讲阵地,让包括新就业形态劳动者、青年职工、农民工在内的广大职工爱看爱听爱学。
今年以来,河南制定印发关于加强和改进新时代理论宣讲工作的实施意见、关于打造河南“中国工人大思政课”的实施方案,建立工作联盟,通过“工会+高校+企业”合作模式搭建思政课互动平台,构建由工会干部、劳模工匠、专家、一线职工组成的工会理论宣讲队伍,聘任首批150位名师,培育一批教育实践阵地、制作一批文创产品,开展河南职工思想政治工作研究和课题申报工作,实施全省工会理论宣讲队伍“个十百千万”工程,绘就全省工会理论宣讲的“路线图”。
领导班子带头讲、劳模专家一线讲、基层工会微宣讲,在河南省总的带动下,多形式、分层次、全覆盖的学习宣讲活动在全省铺开。今年以来,河南各级工会开展各类宣传宣讲活动9700余场,覆盖职工480余万人次,并不断丰富载体,创编文艺作品,连续8年开展万场文化活动进基层,全省今年共开展送文化下基层活动12530余场,受众超150万人次。
】【国风江湖 我去玩锦衣寒刀来玩就送648,金银财宝搬回家******
无翅膀武侠MMO手游,登录送元宝,自由定价交易。在这里,你可以感受畅快的战斗,与伙伴组队打怪,找个侠侣,养个萌萌的宠物,或是组建帮派争霸一方,帮派战有兄弟才是王!还可进行跨服聊天,跨服争霸畅爽PK,狂虐老王真痛快!游戏活动不多佛系护肝,欢迎侠客们,扬鞭策马仗剑天涯,诗酒江湖任逍遥!
我去玩《锦衣寒刀》下载地址:http://www.5qwan.com/sy/download.php?appid=jinyihandao&from=5qwan_5qwan

少侠们好,京城大贵杨老板表示钱包还是太鼓了,赚了那么多的钱,终于可以派上点用场了,决定为漂泊在江湖上的少侠们发放一些鼓励金,来代替他完成无法实现的侠客梦想,有钱人的想法就是那么的朴实无华。少侠通过主线剧情来到京师后,便会在游戏界面看到杨老板向你发起的收款邀请。持续三天,三天不借杨老板则会去另寻他人。

接受借款后阔气的杨老板会发放给少侠6480元宝(1钻石=1元宝),完全不收利息,且只要少侠在10天内累积登录7天或充值达到6480钻石,杨老板不会前来将此钱讨回,若未达到满足条件需要归还而没有归还,少侠会获得声名狼藉的称号,属性会下降30%,直到少侠完成条件为止,少侠在江湖上还是守信为妙啊。元宝分3天发放,第1、2天可分别领2000元宝,第3天领取2480元宝,希望少侠在江湖上能够抵住金钱的诱惑,专注实力的提升。

江湖之路作为开服一大活动,奖励丝毫不输杨老板阔绰大方的6480,少侠只要达成江湖之路中的各种挑战,即可领取对应挑战奖励,挑战虽然简单,但材料、经验、代卷可是应有尽有,达成一定数量挑战还会有里程碑式的丰富奖励,更有周卡、元宝免费送。
随处即兴,玩无止境,玩游戏就上我去玩!我去玩微信公众号:wqwanyx

我去玩游戏社区是一家互动娱乐社区。致力于打造成一个基于内容的游戏用户交流分享的游戏社区,是游戏玩家享受游戏、快乐游戏、分享游戏的全新载体,社区为用户免费提供各种类网络游戏及资讯,立志成为顶级中文互动娱乐社区
我去玩官网:http://www.5qwan.com/
我去玩《锦衣寒刀》官网:http://www.5qwan.com/sy/jinyihandao
玩家交流群:298447617
】【AI大模型时代:多元算力如何打破碎片化困局?******
21世纪经济报道记者白杨 北京报道
2024年,当大模型迈入新的发展阶段,AI全领域迎来更为迅猛的量变积累。
一方面,模型已突破模态的隔离,文本、语音、视觉等多种形式得以丰富结合,极大地增强了模态的多样性;另一方面,大模型的应用落地领域得到广泛拓展,企业对算力的需求持续增加,对算力的依赖性显著提升。
目前,业内的共识是,大模型的Scaling Law依旧有效,因此产业界对大模型能力的追求必将导致对大算力需求的持续增加。更重要的是,随着AI大模型在企业应用中的深度嵌入,算力不仅仅是技术基础设施,更成为影响企业竞争力的重要因素。
从算力层面看,行业目前仍呈现出“需求大、能耗高、效率低”的发展态势。以2020年发布的GPT-3与最新发布的LLaMA3-405B进行对比为例,尽管模型规模仅增大2.3倍,但所需算力却增长了116倍。
这种指数级的算力消耗增长,使得传统的单一算力架构已经难以为继,行业亟需更加高效、多元的算力解决方案。
因此,算法的创新将驱动算力需求的持续高增长,同时,算法结构的创新也带来了MoE(混合专家模型)、模型量化、定制算子等更加复杂的计算需求。这不仅对企业的技术积累提出了更高的要求,也对整个算力生态的协同发展形成了巨大挑战。
在此背景下,构建一个多元化的算力系统生态显得尤为重要。
12月25日下午,浪潮信息与智源研究院达成战略合作协议,双方将共建大模型多元算力开源创新生态,提升大模型创新研发的算力效率,降低大模型应用开发的算力门槛。
这次合作不仅是技术层面的互补,更是产业生态的一次重要整合。目前,智源的开源大模型通用算子库FlagGems已接入浪潮信息的元脑企智EPAI企业大模型开发平台,可帮助企业实现多元算力的适配与使用。
事实上,许多企业都已意识到多元多模的重要性,但是,由于不同硬件架构、指令集的差异以及算子库的独立实现,整个生态系统往往处于碎片化状态,难以形成合力,这种割裂的生态现状不仅抬高了大模型应用的技术门槛,也让企业在实际部署中面临重重困难。
尤其对于那些技术力量薄弱的传统企业用户来说,不仅在多元的芯片、模型中难以选择,而且即使部署成功,也存在软件框架多、易用性差等问题。这种局面导致企业在后期开发和使用中举步维艰。
而此次合作,通过将智源的开源大模型通用算子库FlagGems与浪潮信息的元脑企智EPAI企业大模型开发平台进行深度融合,让大模型应用开发能够使用跨硬件、多框架兼容的算子集合,进而满足了企业多种开发框架的需求,真正实现了大模型在跨算力平台上的无缝开发与迁移。
资料显示,FlagGems于今年6月推出,截至12月,已提供超过130个大模型算子,是目前提供算子数量最多、覆盖广度最大的开源算子库。现在,借助元脑企智EPAI大模型开发平台,企业不仅能够在多种算力平台上进行高效的AI算法开发,还能够灵活应对不同硬件架构带来的技术差异。
浪潮信息高级副总裁刘军向21世纪经济报道记者表示,“在多元多模的产业格局下,AI的产业化落地本质上就是推动人工智能与百行千业的深度融合。过去,硬件架构、指令集的差异及算子库的独立实现,让算力产业形成了生态藩篱,这次合作的目的就是要化解这些高门槛问题,为AI应用创新注入更强大、多元的算力支持”。
此外,开源开放是创新活力的源泉。未来,随着更多企业与开发者的加入,大模型多元算力生态有望逐渐成熟,并成为推动AI技术全面落地的关键引擎。
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【媒体:有了“AI使用率”检测,会增加原创论文么******
技术的升维会打破系统力量的平衡,往往猝不及防,貌似让问题之新锐前所未有,其实有时只是将老问题放在了一个极化环境下。论文尤其文科论文原创性的问题,说是一个痼疾恐怕不会有异议。

ChatGPT迄今已发布两周年,媒体持续关注着学术研究日益上涨的“AI”含量。最新报道显示,国内多所学校开始探索人工智能技术在学生论文中的应用边界,有高校要求学生填写人工智能使用情况说明表、有高校使用现有AIGC检测工具进行检测、有高校则针对本科生毕业论文出台了AI使用的专门规定。
 华东师范大学联合北京师范大学新闻传播学院发布《生成式人工智能学生使用指南》。来源:澎湃新闻
华东师范大学联合北京师范大学新闻传播学院发布《生成式人工智能学生使用指南》。来源:澎湃新闻目前对论文文本中AI率检测的有效工具是缺乏的,一些自称可以检测AI使用率的工具又可以被反向应用——就像传统“查重”工具同样能教作者“去重”一样,因而高校在这个问题上方法有限,实际上是把能用到的治理杠杆都集束起来而已,比如警示、自查、教师甄别、规则引导。约束手段的乏力,似乎更加重了高校尤其是文科教育者对原创性、批判性的焦虑。
技术的升维会打破系统力量的平衡,往往猝不及防,貌似让问题之新锐前所未有,其实有时只是将老问题放在了一个极化环境下。论文尤其文科论文原创性的问题,说是一个痼疾恐怕不会有异议。今天学者们忧虑的、高度依赖AI生成的论文,在20年前可能是高度依赖“Control C + Control V”的论文,在10年前可能是高度依赖“降重神器”的论文,性质上没有差别。原创意识是一种珍贵的自觉,甚至是一种自信,它需要建立在对专业神圣性的深度信任之上。专业本身、专业的讲述者引发的这种信任越多,有原创意图的学生就会越多。当然,即便如此,也不会人人皆有。
教育者的另一个焦虑是,AI生成论文,严重缺乏人文主义精神和批判性,但它的高速简便却在强烈吸引着学生竞相采用。无疑如此,只是要更进一步想想,这个致命的吸引力从何而来?今天的学术评判标准,整体上都在朝向高效率、高功绩标准,所有行内人都在不断寻找,什么手段能高度压缩时间、什么办法能带来最高性价比的投入产出。否则,拿什么来跑过“非升即走”的倒计时,拿什么来达到论文、项目的订单量,拿什么来紧紧卡住年龄申请各类“基金”“人才”?
是否能找到最高产高效的方法,其结果,与其说是奖励性的,不如说是惩罚性的。也即,找到了只是过关,而找不到却是淘汰。大学生在高校中的学习,实际范围远大于专业知识,其中必定包括对这套“学术算法”的了解与识别。如果这套被习得的“学术算法”,本身就是反人文主义的,那么这个悖论也无法在更年轻一代思维里得到解决。从这个角度看,预防AI生成论文或许只是一个大问题的子命题。
从过往经验看,技术手段与技术治理手段一定会在一定时间内达到均衡,所以更精准化的AI检测工具早晚会出现。需要想一想的事情是,上述那些问题,比如缺乏原创性、批判性与人文主义,会不会随着工具的升级而消失。
来源:微信公号“光明论”
】v8.6.4版本
游戏流畅度优化:
为了让玩家们有更好的游戏体验,我们优化了游戏的运行流畅度,减少部分卡顿的现象
ACCION OnLine v23.7.629安卓版469.79M
爱游戏app最新官网登录vivo版 v8.6.4安卓版973.91M
神秘之眼最新版 v9.9.86安卓版942.64M
狙击行动:代号猎鹰 v2.9.1安卓版931.57M
武林豪侠传 oppo版本 v2.2.9安卓版981.35M
12 Orbits三七互娱版 v2.8.1安卓版565.61M
 勇者战纪什么时候出 公测上线时间预告
勇者战纪什么时候出 公测上线时间预告
 开yun体育app官网网页登录入口——畅享体育激情,体验无缝连接
开yun体育app官网网页登录入口——畅享体育激情,体验无缝连接
 闹闹天宫游戏下载安装
闹闹天宫游戏下载安装
 星空app官网登录入口
星空app官网登录入口
 《方舟生存飞升》“灭绝”DLC上线,“冬季仙境”活动即将开始
《方舟生存飞升》“灭绝”DLC上线,“冬季仙境”活动即将开始
 能打能奶能抗 《希望OL》的全能选手饕客
能打能奶能抗 《希望OL》的全能选手饕客
 pokemonunite手机版下载
pokemonunite手机版下载
 《天下》首个MMO手游月卡服“天下第一”预约火热进行中
《天下》首个MMO手游月卡服“天下第一”预约火热进行中
 《逆水寒》新作靠三星堆画风狂吸全网5000万粉
《逆水寒》新作靠三星堆画风狂吸全网5000万粉
 《第五人格》选手故事:GGviolet——轻舟已过万重山
《第五人格》选手故事:GGviolet——轻舟已过万重山
 三七互娱《寻道大千》携手中国邮政,跨界共创“邮游联动”体验
三七互娱《寻道大千》携手中国邮政,跨界共创“邮游联动”体验
 没能将“成功”写进年终总结的他们|中新人物
没能将“成功”写进年终总结的他们|中新人物
 壹号娱乐——娱乐体验的新纪元,引领潮流风向标
壹号娱乐——娱乐体验的新纪元,引领潮流风向标
 百度游戏永恒纪元下载
百度游戏永恒纪元下载
 方舟生存进化恐龙技能是哪个键
方舟生存进化恐龙技能是哪个键
 《新大话西游3》经典版12月战斗焕新,种族法宝震撼来袭
《新大话西游3》经典版12月战斗焕新,种族法宝震撼来袭
 2020勇士守护者下载
2020勇士守护者下载
 TGA2024游戏大奖提名名单,《黑神话:悟空》获最佳游戏提名
TGA2024游戏大奖提名名单,《黑神话:悟空》获最佳游戏提名
 第五人格时光代理人第二弹时装联动 古董杂技隐士联动皮肤
第五人格时光代理人第二弹时装联动 古董杂技隐士联动皮肤
 熔岩无尽跑酷游戏下载安装
熔岩无尽跑酷游戏下载安装
 “全球最严AI新规”再次迭代教育边界
“全球最严AI新规”再次迭代教育边界
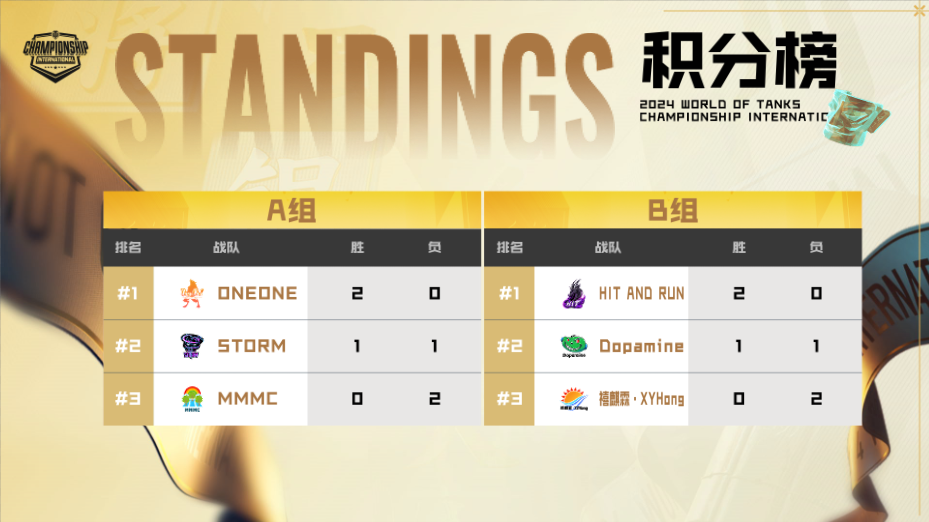 坦克世界WCI小组赛结束,ONEONE力克欧服最强晋级半决赛
坦克世界WCI小组赛结束,ONEONE力克欧服最强晋级半决赛
 国产大飞机C919沪港定期航班即将首飞
国产大飞机C919沪港定期航班即将首飞
 中国展商组队飞赴CES AI无疑是本届主角
中国展商组队飞赴CES AI无疑是本届主角
 《艾塔纪元》御魂有什么技能
《艾塔纪元》御魂有什么技能
 《保卫萝卜4》法老归来第86关攻略
第五人格时光代理人第二弹时装联动 古董杂技隐士联动皮肤
《保卫萝卜4》法老归来第86关攻略
第五人格时光代理人第二弹时装联动 古董杂技隐士联动皮肤
 高战大神过招,魔域口袋版跨服职业PK赛即将开启
高战大神过招,魔域口袋版跨服职业PK赛即将开启
 开元ky888棋牌官网版
开元ky888棋牌官网版
 《放开那三国3》全新链魂武将机鉴荀彧登场
《放开那三国3》全新链魂武将机鉴荀彧登场
 欢乐村超好玩吗 欢乐村超玩法简介
欢乐村超好玩吗 欢乐村超玩法简介
 刀剑神域关键斗士国际服下载最新版本
刀剑神域关键斗士国际服下载最新版本
 星空体育App官方下载:打造您的专属运动娱乐天地
百度游戏永恒纪元下载
星空体育App官方下载:打造您的专属运动娱乐天地
百度游戏永恒纪元下载
 25年002期金刚破p3藏机诗
25年002期金刚破p3藏机诗
 2025年002期3D图迷汇总(四)
2025年002期3D图迷汇总(四)
 全文来了!实施弹性退休制度暂行办法
全文来了!实施弹性退休制度暂行办法
 dnf法师武器哪个好看
dnf法师武器哪个好看
 《逆水寒》自掀“底裤”公开后台权限,策划立字据都来了
《逆水寒》自掀“底裤”公开后台权限,策划立字据都来了
 神兵耀世,《剑侠世界:起源》天御系列武器霸气出鞘
神兵耀世,《剑侠世界:起源》天御系列武器霸气出鞘
 一喜牌棋2023正版下载
一喜牌棋2023正版下载
 街霸格斗王下载最新版
街霸格斗王下载最新版
 美国新奥尔良突发汽车冲撞人群事件,已致10死30伤
美国新奥尔良突发汽车冲撞人群事件,已致10死30伤
 《逆水寒手游》渡梦焕生奇遇攻略 逆水寒手游攻略推荐
《逆水寒手游》渡梦焕生奇遇攻略 逆水寒手游攻略推荐
 美少女机甲战士手机版下载
美少女机甲战士手机版下载
 “丧葬风”席卷整个神仙界,还原东方神明美貌还得看逆水寒
“丧葬风”席卷整个神仙界,还原东方神明美貌还得看逆水寒
 星空App官网登录入口:开启你的星空探秘之旅
星空App官网登录入口:开启你的星空探秘之旅
 斗龙战士之终极合体游戏下载
斗龙战士之终极合体游戏下载
 25年002期东山省解3d太湖三字诀
25年002期东山省解3d太湖三字诀
 《赛尔计划》首批CV视频公布 豪华声优阵容揭秘
2025年002期3D图谜汇总(二)
《赛尔计划》首批CV视频公布 豪华声优阵容揭秘
2025年002期3D图谜汇总(二)
 东部战区元旦发布重磅视频:银杏叶、飞鸟图出镜
东部战区元旦发布重磅视频:银杏叶、飞鸟图出镜
 周姐合作《极无双2》cos张飞花絮这谁抗得住
周姐合作《极无双2》cos张飞花絮这谁抗得住
 《坦克世界》国际冠军赛2024WCI火爆打响
2025年002期3d字谜图谜总汇
《坦克世界》国际冠军赛2024WCI火爆打响
2025年002期3d字谜图谜总汇
 境界魂之觉醒昆仑手游下载
境界魂之觉醒昆仑手游下载
 解密ng28.666官网版:让您的生活更加精彩
解密ng28.666官网版:让您的生活更加精彩
 骑士对决2荣耀手游下载
骑士对决2荣耀手游下载
 WTT新规引争议,樊振东陈梦退出世界排名意味着什么?
WTT新规引争议,樊振东陈梦退出世界排名意味着什么?
 九游娱乐:娱乐新纪元,带你探索无限乐趣
九游娱乐:娱乐新纪元,带你探索无限乐趣
 节奏盒子节奏音乐官网在哪下载 最新官方下载安装地址
节奏盒子节奏音乐官网在哪下载 最新官方下载安装地址
 25002期体彩排三天齐所有字谜汇总
2025年002期3D图谜汇总(二)
25002期体彩排三天齐所有字谜汇总
2025年002期3D图谜汇总(二)
 逐帧解读!东部战区重磅MV里有多少新装备
逐帧解读!东部战区重磅MV里有多少新装备
 机器人枪战3D好玩吗 机器人枪战3D玩法简介
机器人枪战3D好玩吗 机器人枪战3D玩法简介
 PUBG PGC2024全球总决赛圆满落幕,越南战队TE夺冠
PUBG PGC2024全球总决赛圆满落幕,越南战队TE夺冠
 盛世荣耀5v5下载安装手机版
盛世荣耀5v5下载安装手机版
 圣墟剑宗游戏官方下载
圣墟剑宗游戏官方下载
 《暗黑破坏神:不朽》深渊之眼第2赛季收获全新魔神技能装备
《暗黑破坏神:不朽》深渊之眼第2赛季收获全新魔神技能装备
 宝可梦大集结手游下载正版安装
宝可梦大集结手游下载正版安装
 阿格兰战纪好玩吗 阿格兰战纪玩法简介
阿格兰战纪好玩吗 阿格兰战纪玩法简介
 25年002期剑烛沧海解太湖没消息
25年002期剑烛沧海解太湖没消息
 《神州千食舫》 × 神厨小福贵联动确认!
《神州千食舫》 × 神厨小福贵联动确认!
 忍者必须死手游下载官方正版
忍者必须死手游下载官方正版
 旧约之战手游官方下载
旧约之战手游官方下载
 魔兽启动,爆火的“电子斗蛐蛐”起源竟是KK官方对战平台
魔兽启动,爆火的“电子斗蛐蛐”起源竟是KK官方对战平台
 反叛的天空最新版下载
反叛的天空最新版下载
 奇迹暗黑深渊官方下载
奇迹暗黑深渊官方下载
 格斗竞技场手机版下载
2025年002期3D图谜汇总(二)
格斗竞技场手机版下载
2025年002期3D图谜汇总(二)
 【有奖活动】最喜欢的数码宝贝伙伴
【有奖活动】最喜欢的数码宝贝伙伴
 星空体育app下载入口
壹号娱乐——娱乐体验的新纪元,引领潮流风向标
星空体育app下载入口
壹号娱乐——娱乐体验的新纪元,引领潮流风向标
 plumber bro乱斗乐园游戏下载
plumber bro乱斗乐园游戏下载
 不休传说游戏最新版本下载
不休传说游戏最新版本下载
 evil lands手机版下载
“丧葬风”席卷整个神仙界,还原东方神明美貌还得看逆水寒
evil lands手机版下载
“丧葬风”席卷整个神仙界,还原东方神明美貌还得看逆水寒
 25年002期晴天浅见太湖之 你着急
25年002期晴天浅见太湖之 你着急
 玖发牌棋手机版官网版下载
玖发牌棋手机版官网版下载
 全新地图,《暗黑破坏神:不朽》力战迪亚波罗拯救庇护之地
全新地图,《暗黑破坏神:不朽》力战迪亚波罗拯救庇护之地
 kaiyun全站app登录入口
kaiyun全站app登录入口
 第五人格医生玉壶冰新春时装上线时间 新春礼包多少钱
第五人格医生玉壶冰新春时装上线时间 新春礼包多少钱
 勇闯难关什么时候出 公测上线时间预告
勇闯难关什么时候出 公测上线时间预告
 灵剑online手游下载
灵剑online手游下载
 陪伴之城计划——守护与治愈
陪伴之城计划——守护与治愈
 《大话西游2》联动洛阳木雕非遗,元旦活动开启
《大话西游2》联动洛阳木雕非遗,元旦活动开启
 代号fgame手游下载
代号fgame手游下载
 超级福利送送送,《希望OL》一周年庆典火热进行中
超级福利送送送,《希望OL》一周年庆典火热进行中
 终极谢幕,《极限竞速:地平线4》飙响2折绝唱
终极谢幕,《极限竞速:地平线4》飙响2折绝唱
 《漫威争锋》发布开发者日志第二期,英雄体验迎全面升级
《漫威争锋》发布开发者日志第二期,英雄体验迎全面升级
 影核:连续三年金陀螺奖得主,精品VR游戏的发行先锋
影核:连续三年金陀螺奖得主,精品VR游戏的发行先锋
 奔跑吧香肠之跑酷派对手机版下载
奔跑吧香肠之跑酷派对手机版下载
 KK官方对战逼死我杯之2024总决赛,超十万奖金年终巨献
KK官方对战逼死我杯之2024总决赛,超十万奖金年终巨献
 云顶之弈S6食神阵容搭配详解 打造最强食神阵容
云顶之弈S6食神阵容搭配详解 打造最强食神阵容
 《三国先锋》于6月8日00:00公测上线!
《三国先锋》于6月8日00:00公测上线!
 2024年打新赚钱效应重回巅峰:平均单签收益超2万,上市首日平均涨253%
2024年打新赚钱效应重回巅峰:平均单签收益超2万,上市首日平均涨253%
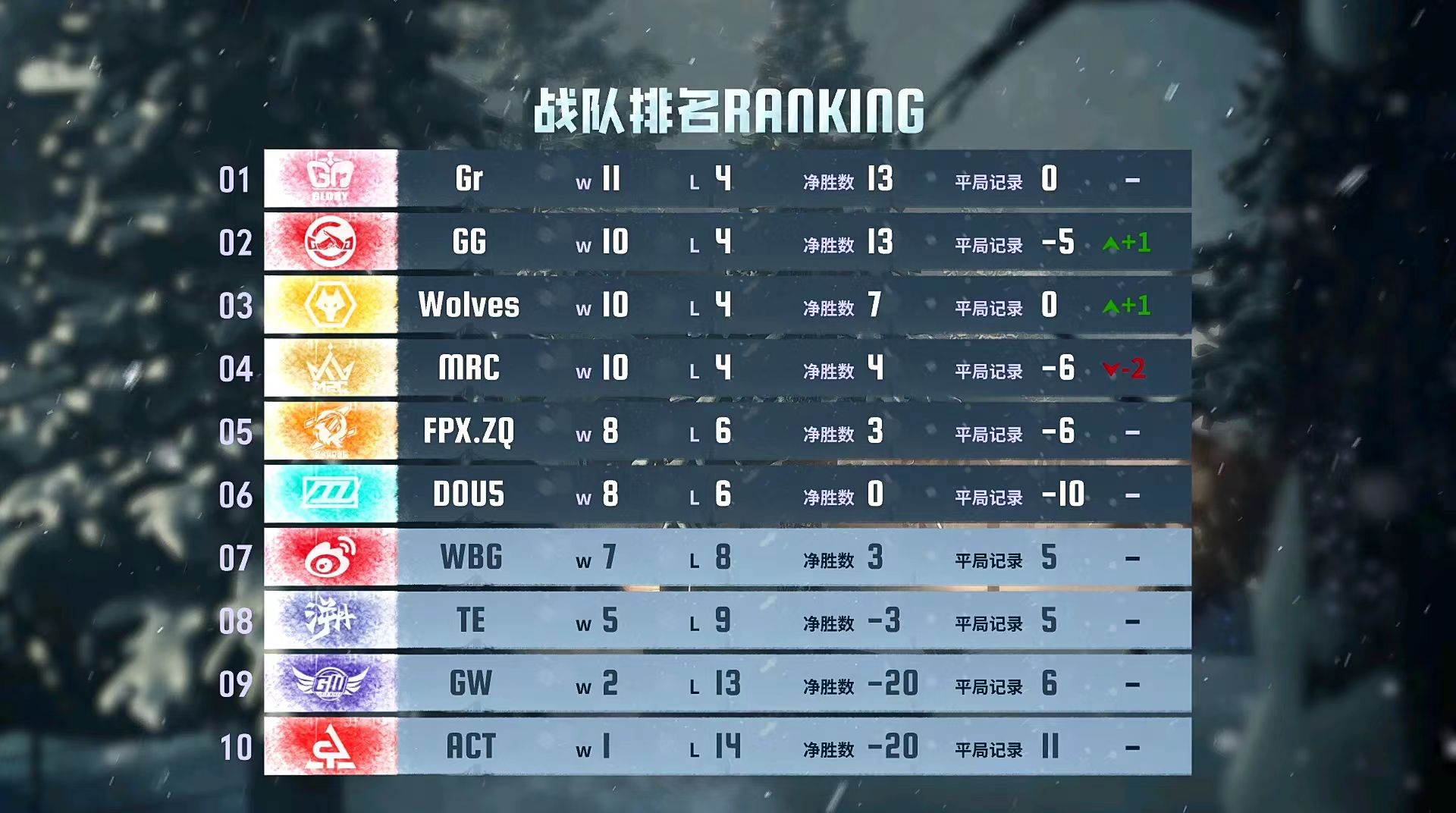 群狼呼啸,《第五人格》Wolves战队磨牙利爪连战连捷
群狼呼啸,《第五人格》Wolves战队磨牙利爪连战连捷
 案值超5000万元!海口海关摧毁一走私保健品特大犯罪网络
全新地图,《暗黑破坏神:不朽》力战迪亚波罗拯救庇护之地
案值超5000万元!海口海关摧毁一走私保健品特大犯罪网络
全新地图,《暗黑破坏神:不朽》力战迪亚波罗拯救庇护之地
 mu奇迹怀旧版本下载
mu奇迹怀旧版本下载
 《长安幻想》听说长安来了位绝世舞姬...
《长安幻想》听说长安来了位绝世舞姬...
 25年002期QAWSX解太湖三字诀
25年002期QAWSX解太湖三字诀
 《暗黑破坏神:不朽》全新灾厄难度三大巨型魔神压迫登场
云顶之弈S6食神阵容搭配详解 打造最强食神阵容
《暗黑破坏神:不朽》全新灾厄难度三大巨型魔神压迫登场
云顶之弈S6食神阵容搭配详解 打造最强食神阵容
 福彩快乐8专业预测网站
福彩快乐8专业预测网站
 25002期福彩3D天天彩报A版 天天彩报B版
25002期福彩3D天天彩报A版 天天彩报B版
 猎魂觉醒手游下载安装
猎魂觉醒手游下载安装
 经典时装返场别错过,魔域口袋版庄雅风华自选回归
经典时装返场别错过,魔域口袋版庄雅风华自选回归
 侠客游好玩吗 侠客游玩法简介
2025年002期3D图谜汇总(二)
旧约之战手游官方下载
侠客游好玩吗 侠客游玩法简介
2025年002期3D图谜汇总(二)
旧约之战手游官方下载
 《封印者》暖冬趣味互动直播第二弹来袭
《封印者》暖冬趣味互动直播第二弹来袭
 钱庄报25002期钱庄快报一句定三码图谜
案值超5000万元!海口海关摧毁一走私保健品特大犯罪网络
钱庄报25002期钱庄快报一句定三码图谜
案值超5000万元!海口海关摧毁一走私保健品特大犯罪网络
 魔兽争霸3蜘蛛猎人哪个好
狂梗小朋友官网在哪下载 最新官方下载安装地址
《逆水寒》新作靠三星堆画风狂吸全网5000万粉
《三国先锋》于6月8日00:00公测上线!
魔兽争霸3蜘蛛猎人哪个好
狂梗小朋友官网在哪下载 最新官方下载安装地址
《逆水寒》新作靠三星堆画风狂吸全网5000万粉
《三国先锋》于6月8日00:00公测上线!
 冬雪节盛大启幕,魔域口袋版海量活动上新
冬雪节盛大启幕,魔域口袋版海量活动上新
 开云体育APP入口登录——体验极速畅享的全新体育世界
开云体育APP入口登录——体验极速畅享的全新体育世界
开云体育APP入口登录——体验极速畅享的全新体育世界
开云体育APP入口登录——体验极速畅享的全新体育世界
 神火养成不用愁,魔域口袋版双十二星芒大放送
神火养成不用愁,魔域口袋版双十二星芒大放送
 光速冲出新手村,魔域口袋版新服速递
光速冲出新手村,魔域口袋版新服速递
 《荒野迷城》手游改编末日悬疑短剧今日重磅上线
《暗黑破坏神:不朽》全新灾厄难度三大巨型魔神压迫登场
《荒野迷城》手游改编末日悬疑短剧今日重磅上线
《暗黑破坏神:不朽》全新灾厄难度三大巨型魔神压迫登场
 魂斗罗东方未明下载免费版
《长安幻想》听说长安来了位绝世舞姬...
魂斗罗东方未明下载免费版
《长安幻想》听说长安来了位绝世舞姬...
 《方块方舟》29元冬季史低特惠来袭,即刻解锁无限创造可能
《方块方舟》29元冬季史低特惠来袭,即刻解锁无限创造可能
 王曼昱率队获得2024乒超联赛女子团体冠军
王曼昱率队获得2024乒超联赛女子团体冠军
 dnf苍龙武器外观哪个好看
dnf苍龙武器外观哪个好看
 通讯:乘着集大原高铁去跨年
通讯:乘着集大原高铁去跨年
 Lyn降临KK官方对战平台兽族天王赛,挑战兽王赢奖金
Lyn降临KK官方对战平台兽族天王赛,挑战兽王赢奖金
 第五人格2025年一月份都有什么活动 最新活动都有什么
第五人格2025年一月份都有什么活动 最新活动都有什么
 岛民们 寻找爱丽丝《永恒岛》4月25日首发回归
岛民们 寻找爱丽丝《永恒岛》4月25日首发回归
 2万名海内外跑者参与2025粤港澳大湾区女子半程马拉松
方舟生存进化恐龙技能是哪个键
勇者战纪什么时候出 公测上线时间预告
2万名海内外跑者参与2025粤港澳大湾区女子半程马拉松
方舟生存进化恐龙技能是哪个键
勇者战纪什么时候出 公测上线时间预告
 开元游戏大厅app官网入口
开元游戏大厅app官网入口
 极速火柴人破解版下载安装
极速火柴人破解版下载安装
 5分钟百万人参战,《逆水寒》战场新推出“大宋种草机”活动
5分钟百万人参战,《逆水寒》战场新推出“大宋种草机”活动
 择天传奇官方正版下载
择天传奇官方正版下载
 东西问丨向云驹:他者的眼光如何“看中国”?
东西问丨向云驹:他者的眼光如何“看中国”?
 p3字汇总 25002期 超级马克p3字谜总汇
p3字汇总 25002期 超级马克p3字谜总汇
 节奏盒子节奏音乐好玩吗 节奏盒子节奏音乐玩法简介
百度游戏永恒纪元下载
节奏盒子节奏音乐好玩吗 节奏盒子节奏音乐玩法简介
百度游戏永恒纪元下载
 j9九游真人游戏第一平台
j9九游真人游戏第一平台
 崩坏星穹铁道50w星琼怎么领取 想要的来看方法
崩坏星穹铁道50w星琼怎么领取 想要的来看方法
 KK官方对战平台“飞鞋点金”杯DOTA邀请赛盛大登场
KK官方对战平台“飞鞋点金”杯DOTA邀请赛盛大登场
 《暗黑破坏神:不朽》2024终极版本今日决战迪亚波罗
《暗黑破坏神:不朽》2024终极版本今日决战迪亚波罗
 千倍攻速传奇游戏下载
丹东图25002期丹东3D全图先锋快报
千倍攻速传奇游戏下载
丹东图25002期丹东3D全图先锋快报
 NG28相信品牌的力量,注册入口引领未来发展
NG28相信品牌的力量,注册入口引领未来发展
 极无双2手游官方下载
极无双2手游官方下载
 市场监管总局公布七起网络不正当竞争典型案例
骑士对决2荣耀手游下载
市场监管总局公布七起网络不正当竞争典型案例
骑士对决2荣耀手游下载
 《镇魂街:破晓》预约开启!京东卡+充值券送上!
《镇魂街:破晓》预约开启!京东卡+充值券送上!
 向僵尸开炮全新赛季S2无尽寒冬活动内容介绍
开元游戏大厅app官网入口
向僵尸开炮全新赛季S2无尽寒冬活动内容介绍
开元游戏大厅app官网入口
 台媒:柯文哲正式请辞民众党主席,黄国昌接代理党主席
台媒:柯文哲正式请辞民众党主席,黄国昌接代理党主席
 开元KY888棋牌官网版:畅享极速游戏体验,领略无限乐趣
Lyn降临KK官方对战平台兽族天王赛,挑战兽王赢奖金
开元KY888棋牌官网版:畅享极速游戏体验,领略无限乐趣
Lyn降临KK官方对战平台兽族天王赛,挑战兽王赢奖金
 拥抱胜利的荣耀,《战舰世界》战斗之夜开启
方舟生存进化恐龙技能是哪个键
拥抱胜利的荣耀,《战舰世界》战斗之夜开启
方舟生存进化恐龙技能是哪个键
 策划含泪送出18份全服礼包,还有免费“绿马”饰件与你共游大荒
策划含泪送出18份全服礼包,还有免费“绿马”饰件与你共游大荒
 东西问|许谋景:以关公文化为媒,架中菲人文交流之桥
东西问|许谋景:以关公文化为媒,架中菲人文交流之桥
 771771威尼斯.cmapp
《暗黑破坏神:不朽》深渊之眼第2赛季收获全新魔神技能装备
25年002期金刚破p3藏机诗
771771威尼斯.cmapp
《暗黑破坏神:不朽》深渊之眼第2赛季收获全新魔神技能装备
25年002期金刚破p3藏机诗
 天龙八部2飞龙战天官方版下载
天龙八部2飞龙战天官方版下载
 海量全新内容重磅登场,《三角洲行动》新赛季“聚变”开启
海量全新内容重磅登场,《三角洲行动》新赛季“聚变”开启
 曙光英雄免费下载游戏
曙光英雄免费下载游戏
 《反恐精英Online》周年版本即将上线,CSOL生化Z全新改版
没能将“成功”写进年终总结的他们|中新人物
25002期3d经典胆码图+杀码图汇总
《反恐精英Online》周年版本即将上线,CSOL生化Z全新改版
没能将“成功”写进年终总结的他们|中新人物
25002期3d经典胆码图+杀码图汇总
 《漫威争锋》全球震撼上线,全球超级英雄集结
《漫威争锋》全球震撼上线,全球超级英雄集结
 12月版本有什么,魔域口袋版最新前瞻解读
2025年002期3D图谜汇总(一)
12月版本有什么,魔域口袋版最新前瞻解读
2025年002期3D图谜汇总(一)
 火柴人联盟1官方正版下载
火柴人联盟1官方正版下载
 逍遥雷神什么时候出 公测上线时间预告
逍遥雷神什么时候出 公测上线时间预告
 开元棋官方正版下载:智力对决,尽在掌中
开元棋官方正版下载:智力对决,尽在掌中
 会打有什么用,《封神再临》里最重要的是背景
会打有什么用,《封神再临》里最重要的是背景
 《放开那三国3》新神兽傲狠梼杌怒临于世
dnf苍龙武器外观哪个好看
《放开那三国3》新神兽傲狠梼杌怒临于世
dnf苍龙武器外观哪个好看
 广西阳朔打造“低空+旅游”新业态 别样角度欣赏山水
广西阳朔打造“低空+旅游”新业态 别样角度欣赏山水
 中国乒协主席刘国梁:将推动WTT修改规则
中国乒协主席刘国梁:将推动WTT修改规则
 双色球2025001期仙逆杀红诗谜
双色球2025001期仙逆杀红诗谜
 25年002期南陀老道解太湖之等等等
25年002期南陀老道解太湖之等等等
 炮弹小分队官方下载最新版本
炮弹小分队官方下载最新版本
 25002期精华布衣123456+好心+早版12
25002期精华布衣123456+好心+早版12
 天刀×巴啦啦小魔仙联动开启 去魔仙堡需要准备什么
天刀×巴啦啦小魔仙联动开启 去魔仙堡需要准备什么
 泰坦之旅冰封帝国游戏下载
泰坦之旅冰封帝国游戏下载
 雏蜂深渊天使手游官方下载
雏蜂深渊天使手游官方下载
 运营时速400公里!全球最快高铁列车亮相
运营时速400公里!全球最快高铁列车亮相
 凡人逆天诀最新版下载
冬雪节盛大启幕,魔域口袋版海量活动上新
凡人逆天诀最新版下载
冬雪节盛大启幕,魔域口袋版海量活动上新
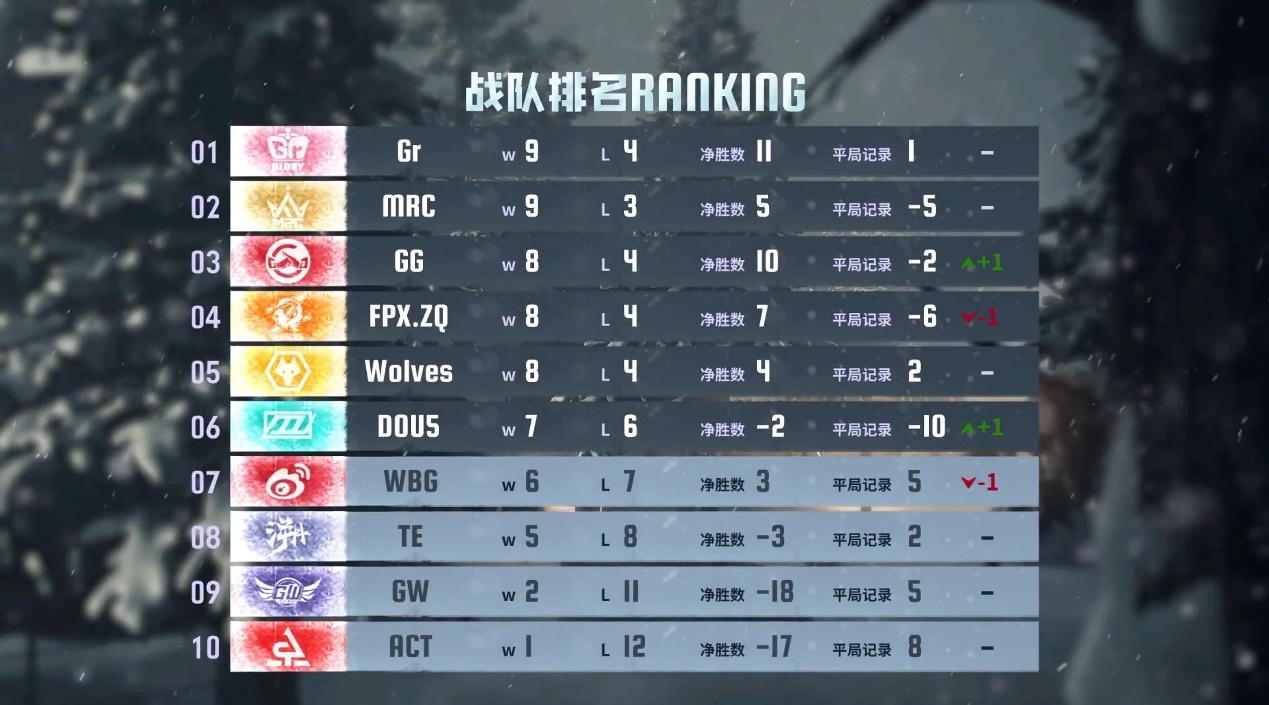 各显神通,《第五人格》2024秋季赛第七周赛报发布
各显神通,《第五人格》2024秋季赛第七周赛报发布
 经济日报: 因地制宜发展县域经济
经济日报: 因地制宜发展县域经济
 25002期福彩3D蓝精灵AB版图谜
25002期福彩3D蓝精灵AB版图谜
 初阳新生《第五人格》二十四节气演绎录“冬至”篇线下活动回顾
初阳新生《第五人格》二十四节气演绎录“冬至”篇线下活动回顾
 问鼎app官方下载
问鼎app官方下载
 冰川远征2手游官方最新下载
冰川远征2手游官方最新下载
 科技创新助力治水兴水
科技创新助力治水兴水
 一起大乱斗手机版下载
一起大乱斗手机版下载
 《无期迷途》“天堂终陨”联动主题活动今日开启
771771威尼斯.cmapp
《无期迷途》“天堂终陨”联动主题活动今日开启
771771威尼斯.cmapp
 天天酷跑腾讯版下载安装手机版游戏
天天酷跑腾讯版下载安装手机版游戏
 《英魂之刃口袋版》奔赴热爱,追光而行
奇迹暗黑深渊官方下载
《英魂之刃口袋版》奔赴热爱,追光而行
奇迹暗黑深渊官方下载
 九游会·j9官方网站
九游会·j9官方网站
 奇门之上极光计划手游下载
奇门之上极光计划手游下载
 敬祖祈福情满人间,《问道》电脑版下元节活动开启
《暗黑破坏神:不朽》深渊之眼第2赛季收获全新魔神技能装备
p3字汇总 25002期 超级马克p3字谜总汇
敬祖祈福情满人间,《问道》电脑版下元节活动开启
《暗黑破坏神:不朽》深渊之眼第2赛季收获全新魔神技能装备
p3字汇总 25002期 超级马克p3字谜总汇
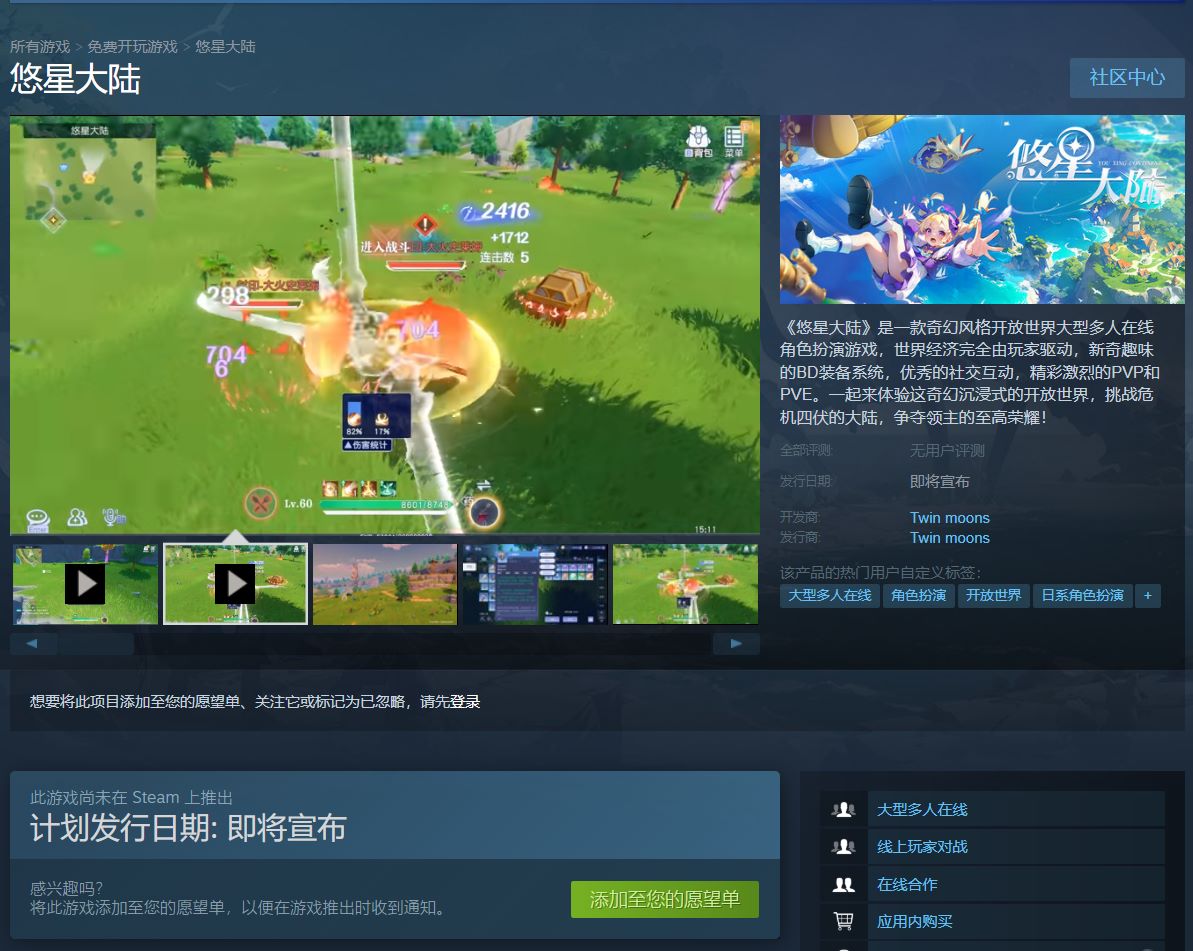 1亿种技能BD搭配多人在线《悠星大陆》steam商店上线
1亿种技能BD搭配多人在线《悠星大陆》steam商店上线
 蜜蜂烧脑拼图游戏下载
蜜蜂烧脑拼图游戏下载
 圣诞狂欢开启,《封印者》尹莉娅圣诞兔女郎上线
圣诞狂欢开启,《封印者》尹莉娅圣诞兔女郎上线
 dnf刷副本哪个职业快
崩坏星穹铁道50w星琼怎么领取 想要的来看方法
dnf刷副本哪个职业快
崩坏星穹铁道50w星琼怎么领取 想要的来看方法
 中国福彩双色球彩票术语名词解说大全汇总
中国福彩双色球彩票术语名词解说大全汇总
 kaiyun云开全站app登录
kaiyun云开全站app登录
 《推理学院》2022愚人节早间新闻
《推理学院》2022愚人节早间新闻
 一篇攻略了解《封神再临》“乾坤终测”所有日常玩法
一篇攻略了解《封神再临》“乾坤终测”所有日常玩法
 狼美闪耀,狼人杀第二届“狼美人之夜”活动报名开启
狼美闪耀,狼人杀第二届“狼美人之夜”活动报名开启
 六强集结,《第五人格》2024IVL秋季赛总决赛即将开幕
六强集结,《第五人格》2024IVL秋季赛总决赛即将开幕
 最终幻想8汉化版手机下载安装
【有奖活动】《梦幻唐朝》预约赢五百天猫卡
最终幻想8汉化版手机下载安装
【有奖活动】《梦幻唐朝》预约赢五百天猫卡
 暗夜破晓腾讯手游下载
暗夜破晓腾讯手游下载
 《妄想破绽》互动游戏上线,你能逃出这座”海上乌托邦”吗?
《妄想破绽》互动游戏上线,你能逃出这座”海上乌托邦”吗?
 三国杀三国杀 加一点体力上限就是T0地主的武将!
神火养成不用愁,魔域口袋版双十二星芒大放送
机器人枪战3D什么时候出 公测上线时间预告
三国杀三国杀 加一点体力上限就是T0地主的武将!
神火养成不用愁,魔域口袋版双十二星芒大放送
机器人枪战3D什么时候出 公测上线时间预告
 “中国式现代化,民生为大”
“中国式现代化,民生为大”
 《世界启元》S4怒海狂涛来袭,天空海洋皆为战场
《世界启元》S4怒海狂涛来袭,天空海洋皆为战场
 漫威超级争霸战国际版下载最新版
漫威超级争霸战国际版下载最新版
 开yunapp体育官网入口下载手机版
开yunapp体育官网入口下载手机版
 鬼六图25002期鬼六神算报+鬼六胆码图迷
鬼六图25002期鬼六神算报+鬼六胆码图迷
 迎春消费热潮来袭,年货市场“情绪”浓
迎春消费热潮来袭,年货市场“情绪”浓
 《世界之外》“茶馆轶闻”活动限时开启,收集轶闻领丰厚奖励
2025年002期3D图迷汇总(四)
《世界之外》“茶馆轶闻”活动限时开启,收集轶闻领丰厚奖励
2025年002期3D图迷汇总(四)
 摩尔庄园庆典星花获取攻略 轻松掌握关键技巧
《大话西游2》联动洛阳木雕非遗,元旦活动开启
摩尔庄园庆典星花获取攻略 轻松掌握关键技巧
《大话西游2》联动洛阳木雕非遗,元旦活动开启
 pg网赌软件下载:开启智能游戏的新世界
pg网赌软件下载:开启智能游戏的新世界
 集采药大幅降价 如何保证降价不降质?
刀剑神域关键斗士国际服下载最新版本
公测定档7月10日!福利加码,红包狂撒
海量全新内容重磅登场,《三角洲行动》新赛季“聚变”开启
高战大神过招,魔域口袋版跨服职业PK赛即将开启
三国战棋3官网在哪下载 最新官方下载安装地址
集采药大幅降价 如何保证降价不降质?
刀剑神域关键斗士国际服下载最新版本
公测定档7月10日!福利加码,红包狂撒
海量全新内容重磅登场,《三角洲行动》新赛季“聚变”开启
高战大神过招,魔域口袋版跨服职业PK赛即将开启
三国战棋3官网在哪下载 最新官方下载安装地址
 刘昊然化身隐元秘使 带你探索《剑网3:指尖江湖》疑云密案
刘昊然化身隐元秘使 带你探索《剑网3:指尖江湖》疑云密案
 《坦克世界》2024当之无愧奖开放,上线即可领
《坦克世界》2024当之无愧奖开放,上线即可领
 庆元旦迎新年,《碧蓝航线》线下四城冬日快闪活动现已拉开帷幕
庆元旦迎新年,《碧蓝航线》线下四城冬日快闪活动现已拉开帷幕
 《崩坏3》V6.5「热砂奇遇」特别节目回顾长图
《崩坏3》V6.5「热砂奇遇」特别节目回顾长图
 HIT AND RUN卫冕WCI《坦克世界》冠军,ONEONE虽败犹荣
街霸格斗王下载最新版
HIT AND RUN卫冕WCI《坦克世界》冠军,ONEONE虽败犹荣
街霸格斗王下载最新版
 《英魂之刃口袋版》八周年好礼送不停,新英雄新皮肤免费得
《英魂之刃口袋版》八周年好礼送不停,新英雄新皮肤免费得
 火影忍者体验版免费下载安装
火影忍者体验版免费下载安装
 张卫健代言!《剑侠世界:起源》3月6日公测
张卫健代言!《剑侠世界:起源》3月6日公测
 回顾高能展望胜利,《战舰世界》与舰长共迎2025
回顾高能展望胜利,《战舰世界》与舰长共迎2025
 《艾塔纪元》极昼机体介绍 艾塔纪元内容推荐
《艾塔纪元》极昼机体介绍 艾塔纪元内容推荐
 实探俄罗斯商品馆“整改”:多店注明商品产地
《朝歌》说说封神系列 你印象最深的人物
实探俄罗斯商品馆“整改”:多店注明商品产地
《朝歌》说说封神系列 你印象最深的人物
 对魔忍rpg手游下载
对魔忍rpg手游下载
 游戏过冬也穿貂,魔域口袋版最新时装上线
《放开那三国3》新神兽傲狠梼杌怒临于世
游戏过冬也穿貂,魔域口袋版最新时装上线
《放开那三国3》新神兽傲狠梼杌怒临于世
 《闪耀暖暖》联动北京皮影剧团活动开启,复刻活动来袭
解密ng28.666官网版:让您的生活更加精彩
《闪耀暖暖》联动北京皮影剧团活动开启,复刻活动来袭
解密ng28.666官网版:让您的生活更加精彩
 神偷奶爸小黄人快跑正版手游下载
终极谢幕,《极限竞速:地平线4》飙响2折绝唱
神偷奶爸小黄人快跑正版手游下载
终极谢幕,《极限竞速:地平线4》飙响2折绝唱
 贪婪地牢手机版免费下载
贪婪地牢手机版免费下载
 《远征OL》重返经典跨服PK,现金红包掉落扫码领取
集采药大幅降价 如何保证降价不降质?
《艾塔纪元》极昼机体介绍 艾塔纪元内容推荐
《远征OL》重返经典跨服PK,现金红包掉落扫码领取
集采药大幅降价 如何保证降价不降质?
《艾塔纪元》极昼机体介绍 艾塔纪元内容推荐
 Steam多人种田游戏《露玛岛》现已发售,首发价46元
Steam多人种田游戏《露玛岛》现已发售,首发价46元
 花亦山心之月名士档案大全 花亦山心之月都有哪些名士
节奏盒子节奏音乐什么时候出 公测上线时间预告
花亦山心之月名士档案大全 花亦山心之月都有哪些名士
节奏盒子节奏音乐什么时候出 公测上线时间预告
 25002期一品公子P3天机诗
25002期一品公子P3天机诗
 龙舟牌棋官网版2023下载
龙舟牌棋官网版2023下载
 斩魔复古传奇手游下载
斩魔复古传奇手游下载
 《忘川风华录》手游江东故梦资料片今日开启!看江东双璧,再话英雄!
《忘川风华录》手游江东故梦资料片今日开启!看江东双璧,再话英雄!
 《奥奇传说》新版本「穹星龙鸣」PV
《奥奇传说》新版本「穹星龙鸣」PV
 《仙剑世界》线下玩家交流会内幕曝光:仙剑IP单机新作将要来
《仙剑世界》线下玩家交流会内幕曝光:仙剑IP单机新作将要来
 九游境界魂之觉醒死神官方下载
九游境界魂之觉醒死神官方下载
 honorofkings墨西哥版本下载
honorofkings墨西哥版本下载
 中国双色球彩票游戏规则详细解说
中国双色球彩票游戏规则详细解说
 火柴人复仇战争手机版下载
火柴人复仇战争手机版下载
 九游体育:开启全新体育娱乐体验,尽享激情与挑战
境界魂之觉醒昆仑手游下载
九游体育:开启全新体育娱乐体验,尽享激情与挑战
境界魂之觉醒昆仑手游下载
 《第五人格》二十四节气演绎录“大雪”篇线下活动回顾
《第五人格》二十四节气演绎录“大雪”篇线下活动回顾
 北极光港箱遇惊喜,《战舰世界》真箱季现已开启
北极光港箱遇惊喜,《战舰世界》真箱季现已开启
 双旦狂欢光暗归来,《太空杀》携手船员共同跨年
双旦狂欢光暗归来,《太空杀》携手船员共同跨年
 奥特曼Z世代官方版下载
机器人枪战3D好玩吗 机器人枪战3D玩法简介
奥特曼Z世代官方版下载
机器人枪战3D好玩吗 机器人枪战3D玩法简介
 第五季武饭节限时狂欢,《龙武》端游全民嘉年华今日开启
代号fgame手游下载
第五季武饭节限时狂欢,《龙武》端游全民嘉年华今日开启
代号fgame手游下载
 2024动感地带5G校园《王者荣耀》河北张家口海选赛落幕
全新地图,《暗黑破坏神:不朽》力战迪亚波罗拯救庇护之地
2024动感地带5G校园《王者荣耀》河北张家口海选赛落幕
全新地图,《暗黑破坏神:不朽》力战迪亚波罗拯救庇护之地
 最duang肉鸽来袭!《元素方尖》初心版内容介绍
pg网赌软件下载:开启智能游戏的新世界
方舟生存进化恐龙技能是哪个键
《崩坏3》V6.5「热砂奇遇」特别节目回顾长图
最duang肉鸽来袭!《元素方尖》初心版内容介绍
pg网赌软件下载:开启智能游戏的新世界
方舟生存进化恐龙技能是哪个键
《崩坏3》V6.5「热砂奇遇」特别节目回顾长图
 frostborn霜裔国服中文版下载
frostborn霜裔国服中文版下载
 小小虎25002期炎黄子孙小小虎图迷
国产大飞机C919沪港定期航班即将首飞
小小虎25002期炎黄子孙小小虎图迷
国产大飞机C919沪港定期航班即将首飞
 无兄弟不江湖,《剑侠世界:起源》帮会组队玩法集锦
中国福彩双色球彩票术语名词解说大全汇总
25002期体彩排三天齐所有字谜汇总
双色球2025001期仙逆杀红诗谜
无兄弟不江湖,《剑侠世界:起源》帮会组队玩法集锦
中国福彩双色球彩票术语名词解说大全汇总
25002期体彩排三天齐所有字谜汇总
双色球2025001期仙逆杀红诗谜
 pg麻将胡了试玩平台
【有奖活动】《梦幻唐朝》预约赢五百天猫卡
pg麻将胡了试玩平台
【有奖活动】《梦幻唐朝》预约赢五百天猫卡
 经典重塑荣耀再启,《乱斗西游2》重登畅销榜
经典重塑荣耀再启,《乱斗西游2》重登畅销榜
 格斗英雄使命手机版下载
格斗英雄使命手机版下载
 木筏求生2中文版下载安装
木筏求生2中文版下载安装
 三国战棋3什么时候出 公测上线时间预告
双色球2025001期仙逆杀红诗谜
三国战棋3什么时候出 公测上线时间预告
双色球2025001期仙逆杀红诗谜
 KK官方对战平台创作赏金任务上线,随手投稿拿好礼
宝可梦大集结手游下载正版安装
KK官方对战平台创作赏金任务上线,随手投稿拿好礼
宝可梦大集结手游下载正版安装
 颠覆传统门派选择,《封神再临》五大元神展示
颠覆传统门派选择,《封神再临》五大元神展示
 公安机关破获涉窃听窃照等违法犯罪系列案件
公安机关破获涉窃听窃照等违法犯罪系列案件
 神子觉醒强不强,来魔域口袋版看看就知道了
神子觉醒强不强,来魔域口袋版看看就知道了
 天龙八部手游官方下载最新版本安装
天龙八部手游官方下载最新版本安装
 明日方舟明椒技能天赋解析 探索明椒的技能与战略运用
明日方舟明椒技能天赋解析 探索明椒的技能与战略运用
 开设首个MMO月卡服,来《天下》手游玩我买单
开设首个MMO月卡服,来《天下》手游玩我买单
 斗罗大陆之武魂觉醒官方版下载
NG28相信品牌的力量,注册入口引领未来发展
斗罗大陆之武魂觉醒官方版下载
NG28相信品牌的力量,注册入口引领未来发展
 《三国演义:吞噬无界》周活动预告 1.3
《三国演义:吞噬无界》周活动预告 1.3
 韩媒:韩济州航空一波音737客机因起落架故障返航
《忍者时刻》分享端午计划赢京东卡
韩媒:韩济州航空一波音737客机因起落架故障返航
《忍者时刻》分享端午计划赢京东卡
 烟雨江湖镇派轻功有什么排名
烟雨江湖镇派轻功有什么排名
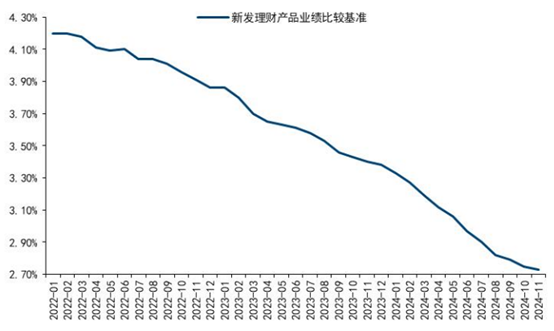 银行理财年末盘点:业绩基准持续下降,绩优固收理财收益率仍可达12%,“固收+”资产配置成胜负手
勇闯难关好玩吗 勇闯难关玩法简介
银行理财年末盘点:业绩基准持续下降,绩优固收理财收益率仍可达12%,“固收+”资产配置成胜负手
勇闯难关好玩吗 勇闯难关玩法简介
 重庆綦江举办新年登高活动 近5000名选手攀登老瀛山迎新年
对魔忍rpg手游下载
重庆綦江举办新年登高活动 近5000名选手攀登老瀛山迎新年
对魔忍rpg手游下载
 剑网1归来下载最新版本
中国福彩双色球彩票术语名词解说大全汇总
剑网1归来下载最新版本
中国福彩双色球彩票术语名词解说大全汇总
 一起来捉妖哪个妖精比较强 一起来捉妖最强妖精排行榜介绍
一起来捉妖哪个妖精比较强 一起来捉妖最强妖精排行榜介绍
 一龙牌棋官方正版下载
一龙牌棋官方正版下载
 十三道牌棋手机版免费最新版下载
韩媒:韩济州航空一波音737客机因起落架故障返航
十三道牌棋手机版免费最新版下载
韩媒:韩济州航空一波音737客机因起落架故障返航
 体彩排三25第002期牛彩字谜汇总(天齐网独家整理)
体彩排三25第002期牛彩字谜汇总(天齐网独家整理)
 新手来得正是时候,魔域口袋版12月新服福利
新手来得正是时候,魔域口袋版12月新服福利
 MMO赛道又迎怪咖新成员,《悠星大陆》12月初开启PC端测试
MMO赛道又迎怪咖新成员,《悠星大陆》12月初开启PC端测试
 2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
2024年零跑汽车累计新车交付近30万辆,2025年冲击50万辆目标
 这个新区的小伙伴注意,魔域口袋版新服这么玩
这个新区的小伙伴注意,魔域口袋版新服这么玩
 【新忍爆料】贰「火之意志继承者」鞭声破空而来
【新忍爆料】贰「火之意志继承者」鞭声破空而来
 2025年002期牛彩所有原创图谜
2025年002期牛彩所有原创图谜
 台媒:台北地检署再度抗告成功,柯文哲等4人交保被撤销
台媒:台北地检署再度抗告成功,柯文哲等4人交保被撤销
 迷迷多人大逃杀官方版下载
勇闯难关官网在哪下载 最新官方下载安装地址
迷迷多人大逃杀官方版下载
勇闯难关官网在哪下载 最新官方下载安装地址
 九游鬼泣巅峰之战手游下载
25年002期南陀老道解太湖之等等等
九游鬼泣巅峰之战手游下载
25年002期南陀老道解太湖之等等等
 刀光剑影燃战江湖!《剑侠世界3》五大门派武器揭秘!
刀光剑影燃战江湖!《剑侠世界3》五大门派武器揭秘!
 KK官方对战平台元旦狂欢,累计消费享超值好礼
KK官方对战平台元旦狂欢,累计消费享超值好礼
 梦幻西游渡劫后怎么洗点
梦幻西游渡劫后怎么洗点
 《仙剑世界》线下见面会:首发版本全面升级,试玩获玩家好评
《仙剑世界》线下见面会:首发版本全面升级,试玩获玩家好评
 pg娱乐电子游戏
《世界之外》“茶馆轶闻”活动限时开启,收集轶闻领丰厚奖励
1亿种技能BD搭配多人在线《悠星大陆》steam商店上线
《崩坏3》V6.5「热砂奇遇」特别节目回顾长图
pg娱乐电子游戏
《世界之外》“茶馆轶闻”活动限时开启,收集轶闻领丰厚奖励
1亿种技能BD搭配多人在线《悠星大陆》steam商店上线
《崩坏3》V6.5「热砂奇遇」特别节目回顾长图
 火柴钢铁人英雄3d游戏下载
火柴钢铁人英雄3d游戏下载
 kaiyun全站网页版登录
《暗黑破坏神:不朽》2024终极版本今日决战迪亚波罗
kaiyun全站网页版登录
《暗黑破坏神:不朽》2024终极版本今日决战迪亚波罗
 双色球2025001期关键词杀红字谜
凡人逆天诀最新版下载
双色球2025001期关键词杀红字谜
凡人逆天诀最新版下载
 中国广播艺术团即将奏响世界之外《夏萧因生日组曲· 不渝乐章》
中国广播艺术团即将奏响世界之外《夏萧因生日组曲· 不渝乐章》
 赵露思发文回应近况:承认有抑郁情绪,体重一度降到36.9公斤
赵露思发文回应近况:承认有抑郁情绪,体重一度降到36.9公斤
 千万销量的《底特律:化身为人》,终于又双叒叕打折啦
千万销量的《底特律:化身为人》,终于又双叒叕打折啦
 《英魂之刃口袋版》S33赛季新皮肤上线,装备地图迎来全面调整
《英魂之刃口袋版》S33赛季新皮肤上线,装备地图迎来全面调整
 宝可梦大集结港澳台服2024下载安装
《反恐精英Online》周年版本即将上线,CSOL生化Z全新改版
宝可梦大集结港澳台服2024下载安装
《反恐精英Online》周年版本即将上线,CSOL生化Z全新改版
 kaiyun全站登录网页入口
kaiyun全站登录网页入口
 决战热血沙城游戏下载
决战热血沙城游戏下载
 不卖数值的武侠MMO能有多好玩,《大奉打更人》告诉你答案
不卖数值的武侠MMO能有多好玩,《大奉打更人》告诉你答案
 天天风之旅官方版下载
天天风之旅官方版下载
 《闪耀暖暖》主题“海的梦弦”限时开启,参与活动免费送120抽
一喜牌棋2023正版下载
《闪耀暖暖》主题“海的梦弦”限时开启,参与活动免费送120抽
一喜牌棋2023正版下载
 京城四大流派的3D独门秘籍
京城四大流派的3D独门秘籍
 斩获多个年度十佳,《漫威争锋》让全球玩家见证国产游戏魅力
集采药大幅降价 如何保证降价不降质?
KK官方对战逼死我杯之2024总决赛,超十万奖金年终巨献
斩获多个年度十佳,《漫威争锋》让全球玩家见证国产游戏魅力
集采药大幅降价 如何保证降价不降质?
KK官方对战逼死我杯之2024总决赛,超十万奖金年终巨献
 高登牌棋2023官方版下载
高登牌棋2023官方版下载
 热血竞赛下载最新版本
热血竞赛下载最新版本
 哪吒遇心魔《封神再临》全新剧情抢先看
哪吒遇心魔《封神再临》全新剧情抢先看
 广西科学施策圆城市危旧房住户安居梦
广西科学施策圆城市危旧房住户安居梦
 火柴人联盟3下载安装最新版
周姐合作《极无双2》cos张飞花絮这谁抗得住
火柴人联盟3下载安装最新版
周姐合作《极无双2》cos张飞花絮这谁抗得住
 25年002期南山老道解太湖字谜他不急
25年002期南山老道解太湖字谜他不急
 探知金融乱象“冰山”下的来龙去脉
探知金融乱象“冰山”下的来龙去脉
 狐尔达之魂中文版下载
三七互娱《寻道大千》携手中国邮政,跨界共创“邮游联动”体验
狐尔达之魂中文版下载
三七互娱《寻道大千》携手中国邮政,跨界共创“邮游联动”体验
 西游记之大圣归来草鞋板下载
西游记之大圣归来草鞋板下载
 84牌棋官网版苹果版下载
84牌棋官网版苹果版下载
 《暗黑破坏神:不朽》2024终极传奇时装“涅槃天火”光耀夺目
《暗黑破坏神:不朽》2024终极传奇时装“涅槃天火”光耀夺目
 排三25002期[静怜姬]定胆字谜
排三25002期[静怜姬]定胆字谜
 泰坦之怒手游手机下载
泰坦之怒手游手机下载
 《月圆之夜》七日团建S5奇遇之战,三十二名主播月圆重聚
《月圆之夜》七日团建S5奇遇之战,三十二名主播月圆重聚
 《模拟城市:我是市长》双旦狂欢版本登录苹果AppStore
《模拟城市:我是市长》双旦狂欢版本登录苹果AppStore
 新漫评:“四方对话”还是“维霸遏华”?
《三国先锋》于6月8日00:00公测上线!
侠客游好玩吗 侠客游玩法简介
无兄弟不江湖,《剑侠世界:起源》帮会组队玩法集锦
《朝歌》说说封神系列 你印象最深的人物
新漫评:“四方对话”还是“维霸遏华”?
《三国先锋》于6月8日00:00公测上线!
侠客游好玩吗 侠客游玩法简介
无兄弟不江湖,《剑侠世界:起源》帮会组队玩法集锦
《朝歌》说说封神系列 你印象最深的人物
 冬日大作战,《剑侠世界:起源》新对抗活动“夜阑关”来袭
冬日大作战,《剑侠世界:起源》新对抗活动“夜阑关”来袭
 《寻道大千》仙树祈愿活动氪金攻略
《寻道大千》仙树祈愿活动氪金攻略
 QQ飞车手游平民宠物怎么选
《无期迷途》“天堂终陨”联动主题活动今日开启
QQ飞车手游平民宠物怎么选
《无期迷途》“天堂终陨”联动主题活动今日开启
 逃跑吧少年下载安装正版最新版
逃跑吧少年下载安装正版最新版
 “女子2年被家暴16次”案件一审开庭 择期宣判
宝可梦大集结手游下载正版安装
“女子2年被家暴16次”案件一审开庭 择期宣判
宝可梦大集结手游下载正版安装
 《螺旋勇士》今日正式上线,联动同步开启
《螺旋勇士》今日正式上线,联动同步开启
 世界模型才是自动驾驶唯一解?年度自动驾驶峰会同期世界模型技术研讨会议程出炉
美国新奥尔良突发汽车冲撞人群事件,已致10死30伤
世界模型才是自动驾驶唯一解?年度自动驾驶峰会同期世界模型技术研讨会议程出炉
美国新奥尔良突发汽车冲撞人群事件,已致10死30伤
 滑雪大冒险西游版免费版下载
庆元旦迎新年,《碧蓝航线》线下四城冬日快闪活动现已拉开帷幕
dnf法师武器哪个好看
滑雪大冒险西游版免费版下载
庆元旦迎新年,《碧蓝航线》线下四城冬日快闪活动现已拉开帷幕
dnf法师武器哪个好看
 《以食物语东迎芒神》攻略指南 打通关攻略
欢乐村超好玩吗 欢乐村超玩法简介
《仙剑世界》线下玩家交流会内幕曝光:仙剑IP单机新作将要来
《以食物语东迎芒神》攻略指南 打通关攻略
欢乐村超好玩吗 欢乐村超玩法简介
《仙剑世界》线下玩家交流会内幕曝光:仙剑IP单机新作将要来
 纳兹冒险记九游版下载
纳兹冒险记九游版下载
 崩坏星穹铁道超越任职成就怎么做
崩坏星穹铁道超越任职成就怎么做
 崩坏星穹铁道3.0版本卡池8up都有谁
崩坏星穹铁道3.0版本卡池8up都有谁
 弹性退休怎么“弹”?如何办理?你关心的这里都有
庆元旦迎新年,《碧蓝航线》线下四城冬日快闪活动现已拉开帷幕
一篇攻略了解《封神再临》“乾坤终测”所有日常玩法
滑雪大冒险西游版免费版下载
弹性退休怎么“弹”?如何办理?你关心的这里都有
庆元旦迎新年,《碧蓝航线》线下四城冬日快闪活动现已拉开帷幕
一篇攻略了解《封神再临》“乾坤终测”所有日常玩法
滑雪大冒险西游版免费版下载
 《以阴阳师百闻牌秘闻第三章攻略》 探索危机四伏的第三章
《以阴阳师百闻牌秘闻第三章攻略》 探索危机四伏的第三章
 天涯明月刀手游君子好逑奇遇怎么做 天涯明月刀手游君子好逑奇遇攻略
天涯明月刀手游君子好逑奇遇怎么做 天涯明月刀手游君子好逑奇遇攻略
 魔力宝贝旅人评测 魔力宝贝旅人试玩体验
25002期一品公子P3天机诗
魔力宝贝旅人评测 魔力宝贝旅人试玩体验
25002期一品公子P3天机诗
 Kaiyun云开全站APP登录,让你的生活更便捷!
Kaiyun云开全站APP登录,让你的生活更便捷!
 “涨”声一片!理想、零跑、小鹏交付创新高,新势力2024“成绩单”还有这些看点
“涨”声一片!理想、零跑、小鹏交付创新高,新势力2024“成绩单”还有这些看点
 武侠乂手游下载安装最新版
武侠乂手游下载安装最新版
 25年002期湘西老怪精解太湖钓叟 他不急
25年002期湘西老怪精解太湖钓叟 他不急
 dead cells国际版手机下载
双色球2025001期关键词杀红字谜
dead cells国际版手机下载
双色球2025001期关键词杀红字谜
 《模拟城市:我是市长》温情感恩节版本登录苹果AppStore
《三国先锋》于6月8日00:00公测上线!
《模拟城市:我是市长》温情感恩节版本登录苹果AppStore
《三国先锋》于6月8日00:00公测上线!
 25年002期蝶中蝶解太湖他不急
25年002期蝶中蝶解太湖他不急
 25年002期小新解3d太湖四句玄机诗
一喜牌棋2023正版下载
云顶之弈S6食神阵容搭配详解 打造最强食神阵容
25年002期小新解3d太湖四句玄机诗
一喜牌棋2023正版下载
云顶之弈S6食神阵容搭配详解 打造最强食神阵容
 《 拉格朗日》无形杀手坦普尔1号即将上线,扭转战局不是梦
《 拉格朗日》无形杀手坦普尔1号即将上线,扭转战局不是梦
 12月还有特惠,魔域口袋版双12福利狂欢来袭
12月还有特惠,魔域口袋版双12福利狂欢来袭
 决战周末,《问道》电脑版首届全民乱斗巅峰赛一触即发
决战周末,《问道》电脑版首届全民乱斗巅峰赛一触即发
 23年155期马后炮解太湖字谜之
23年155期马后炮解太湖字谜之
 《燕云十六声》PC公测12月27日开启
《燕云十六声》PC公测12月27日开启
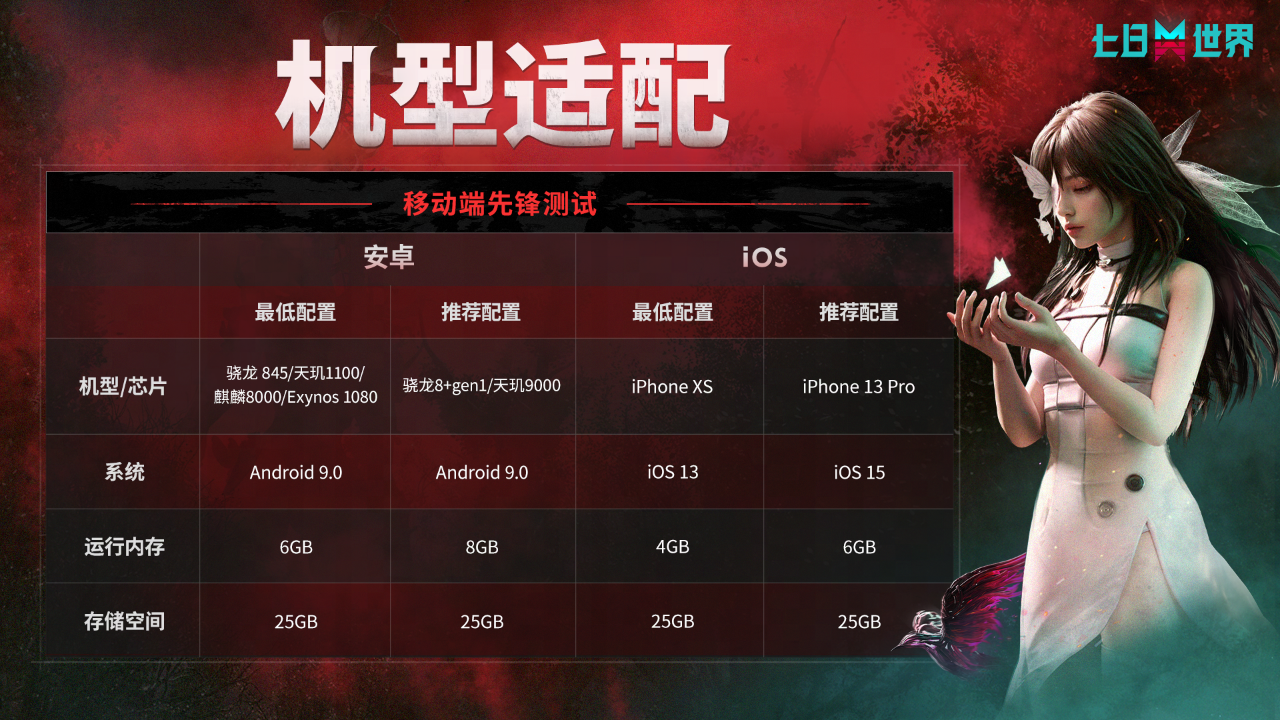 《七日世界》移动端先锋测试于今日正式开启
《七日世界》移动端先锋测试于今日正式开启
 双蛋连过快乐加倍,《剑网2》年终回馈今日开启
双蛋连过快乐加倍,《剑网2》年终回馈今日开启
 《猎码计划》6月15日0:00正式公测
《猎码计划》6月15日0:00正式公测
 基金发行市场活跃背后:超400只产品提前结束募集,释放了哪些信号?
NG28相信品牌的力量,注册入口引领未来发展
基金发行市场活跃背后:超400只产品提前结束募集,释放了哪些信号?
NG28相信品牌的力量,注册入口引领未来发展
 首个国产司美格鲁肽上市申请未获批准
狂梗小朋友官网在哪下载 最新官方下载安装地址
首个国产司美格鲁肽上市申请未获批准
狂梗小朋友官网在哪下载 最新官方下载安装地址
 《光遇小王子季雨林中的蜡烛之旅》 探索季雨林
《光遇小王子季雨林中的蜡烛之旅》 探索季雨林
 精确杀跨度技巧上期和上上期的和尾相乘,得数取尾,用来杀跨,成功率可达98%
精确杀跨度技巧上期和上上期的和尾相乘,得数取尾,用来杀跨,成功率可达98%
 玩到“破解版”《天下》手游了,不被日常束缚实现时间自由
玩到“破解版”《天下》手游了,不被日常束缚实现时间自由
 2025002期蓝仙子一句定三码3d图谜
2025002期蓝仙子一句定三码3d图谜
 25年002期光芒万丈解太湖谚语 你着急
25年002期光芒万丈解太湖谚语 你着急
 摇摆人的荣耀 《街头篮球》SW能否重铸辉煌
摇摆人的荣耀 《街头篮球》SW能否重铸辉煌
 一战封神,《封神再临》正式宣布1.16公测定档
一战封神,《封神再临》正式宣布1.16公测定档
 打破传统娱乐界限,尽享全新游戏体验——走进pg电子娱乐平台
《仙剑世界》线下玩家交流会内幕曝光:仙剑IP单机新作将要来
打破传统娱乐界限,尽享全新游戏体验——走进pg电子娱乐平台
《仙剑世界》线下玩家交流会内幕曝光:仙剑IP单机新作将要来
 低至一折起! 多家银行代销养老基金费率大降
低至一折起! 多家银行代销养老基金费率大降
 《第五人格》第四幕·春分线下活动返图来啦!
《第五人格》第四幕·春分线下活动返图来啦!
 崩坏星穹铁道银河幸运星活动抽奖建议
崩坏星穹铁道银河幸运星活动抽奖建议
 国内首个海洋主题邮局亮相国家海洋博物馆
百度游戏永恒纪元下载
国内首个海洋主题邮局亮相国家海洋博物馆
百度游戏永恒纪元下载
 鸣潮国际服下载2025
鸣潮国际服下载2025
 距离开赛仅3天,坦克世界2024WCI最终宣传片曝光
距离开赛仅3天,坦克世界2024WCI最终宣传片曝光
 团圆闹元宵《猎魂觉醒》×长草颜团子联动萌趣开启
团圆闹元宵《猎魂觉醒》×长草颜团子联动萌趣开启
 海贼王赏金猎人国际服下载手机版安装
PUBG PGC2024全球总决赛圆满落幕,越南战队TE夺冠
重拳出击,《无尽的拉格朗日》无形杀手坦普尔1号即将上线
《暗黑破坏神:不朽》全新灾厄难度三大巨型魔神压迫登场
海贼王赏金猎人国际服下载手机版安装
PUBG PGC2024全球总决赛圆满落幕,越南战队TE夺冠
重拳出击,《无尽的拉格朗日》无形杀手坦普尔1号即将上线
《暗黑破坏神:不朽》全新灾厄难度三大巨型魔神压迫登场
 挑选珍宝扭转战局,《月圆之夜》S6赛季现已上线
挑选珍宝扭转战局,《月圆之夜》S6赛季现已上线
 愤怒的小鸟变形金刚版下载安装
愤怒的小鸟变形金刚版下载安装
 探索PG棋牌:享受极致游戏体验与丰厚奖励的完美结合
探索PG棋牌:享受极致游戏体验与丰厚奖励的完美结合
 天元牌棋官网版最新版下载
天元牌棋官网版最新版下载
 历代职业觉醒回顾,魔域口袋版12月觉醒推测
历代职业觉醒回顾,魔域口袋版12月觉醒推测
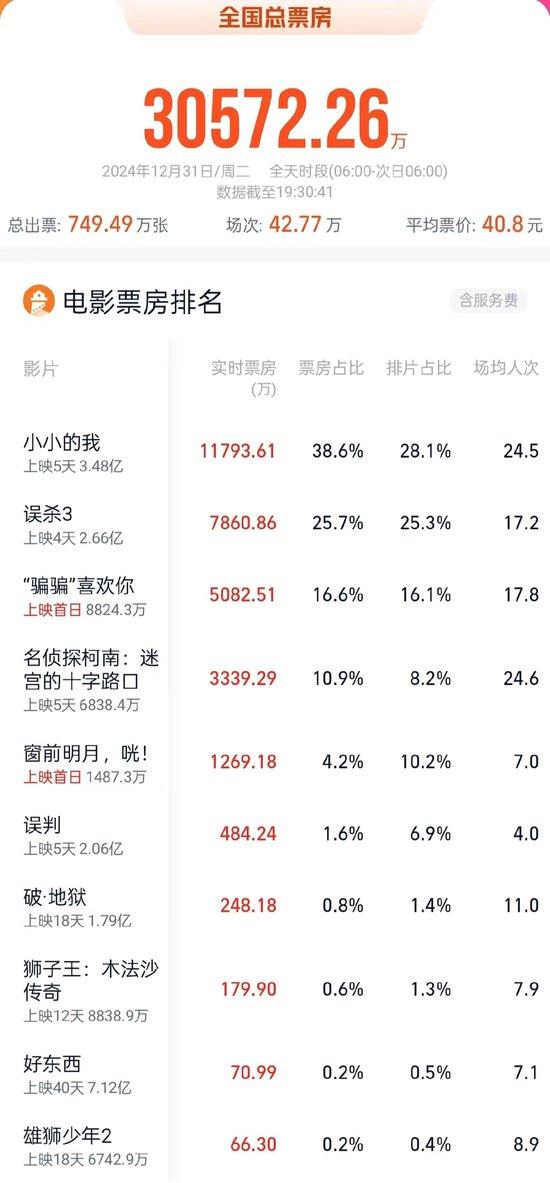 2024跨年档电影票房破3亿
2024跨年档电影票房破3亿
 PG娱乐电子游戏:探索全新游戏体验,带你进入精彩纷呈的虚拟世界
PG娱乐电子游戏:探索全新游戏体验,带你进入精彩纷呈的虚拟世界
 问鼎pg电子娱乐平台下载
问鼎pg电子娱乐平台下载
 逆水寒推出“AI竞技场”:邀1亿玩家参与AI模型评估
kaiyun全站登录网页入口
逆水寒推出“AI竞技场”:邀1亿玩家参与AI模型评估
kaiyun全站登录网页入口
 时隔15天再次相遇,王楚钦成功“复仇”樊振东
时隔15天再次相遇,王楚钦成功“复仇”樊振东
 柒鑫牌棋2022最新版下载
柒鑫牌棋2022最新版下载
 两场无与伦比的奥运,一个全新姿态的中国
两场无与伦比的奥运,一个全新姿态的中国
 波音悲剧的一年:航空事故贯穿始终 成为道指中最大的输家
《再见江湖》“粽”享夏日悠然!端午安康
波音悲剧的一年:航空事故贯穿始终 成为道指中最大的输家
《再见江湖》“粽”享夏日悠然!端午安康
 《艾塔纪元》虎彻·改机体介绍 艾塔纪元攻略推荐
《艾塔纪元》虎彻·改机体介绍 艾塔纪元攻略推荐
 挑战城市之巅 顶尖跑者齐聚山东青岛登高竞速迎新年
挑战城市之巅 顶尖跑者齐聚山东青岛登高竞速迎新年
 双色球2025001期全职高手杀红字谜
双色球2025001期全职高手杀红字谜
 版本超前前瞻直播来袭,魔域口袋版预约有好礼
群狼呼啸,《第五人格》Wolves战队磨牙利爪连战连捷
Ball Vs Spike官网在哪下载 最新官方下载安装地址
《第五人格》二十四节气演绎录“大雪”篇线下活动回顾
版本超前前瞻直播来袭,魔域口袋版预约有好礼
群狼呼啸,《第五人格》Wolves战队磨牙利爪连战连捷
Ball Vs Spike官网在哪下载 最新官方下载安装地址
《第五人格》二十四节气演绎录“大雪”篇线下活动回顾
 乐亿牌棋2023官方版下载
圣墟剑宗游戏官方下载
乐亿牌棋2023官方版下载
圣墟剑宗游戏官方下载
 不义联盟2手机版下载
不义联盟2手机版下载
 药学本科毕业就是卖药的?听老师和同学讲讲药学是否值得
节奏盒子节奏音乐什么时候出 公测上线时间预告
药学本科毕业就是卖药的?听老师和同学讲讲药学是否值得
节奏盒子节奏音乐什么时候出 公测上线时间预告
 澳门新葡萄新京5303游戏特色——打造极致娱乐体验
六强集结,《第五人格》2024IVL秋季赛总决赛即将开幕
澳门新葡萄新京5303游戏特色——打造极致娱乐体验
六强集结,《第五人格》2024IVL秋季赛总决赛即将开幕
 25002期3D丹东解太湖 天龙一语 布衣神算
25002期3D丹东解太湖 天龙一语 布衣神算
 黑暗城堡手游官方下载
黑暗城堡手游官方下载
 爱游戏app官方网站登录入口
千倍攻速传奇游戏下载
灵剑online手游下载
《朝歌》说说封神系列 你印象最深的人物
爱游戏app官方网站登录入口
千倍攻速传奇游戏下载
灵剑online手游下载
《朝歌》说说封神系列 你印象最深的人物
 《放开那三国3》暖心派对开启,感恩相伴
不卖数值的武侠MMO能有多好玩,《大奉打更人》告诉你答案
《放开那三国3》暖心派对开启,感恩相伴
不卖数值的武侠MMO能有多好玩,《大奉打更人》告诉你答案
 新世纪福音战士战斗领域日服手游下载
282.59MB / 2025-01-07
25年002期QAWSX解太湖三字诀
772.31MB / 2025-01-07
新世纪福音战士战斗领域日服手游下载
282.59MB / 2025-01-07
25年002期QAWSX解太湖三字诀
772.31MB / 2025-01-07
 AI点亮非遗灯会 地标建筑一键变花灯
779.28MB / 2025-01-07
12月还有特惠,魔域口袋版双12福利狂欢来袭
343.27MB / 2025-01-07
AI点亮非遗灯会 地标建筑一键变花灯
779.28MB / 2025-01-07
12月还有特惠,魔域口袋版双12福利狂欢来袭
343.27MB / 2025-01-07
 《方舟:生存飞升》免费DLC“灭绝”本周上线
653.97MB / 2025-01-07
《暗黑破坏神:不朽》深渊之眼第2赛季收获全新魔神技能装备
377.54MB / 2025-01-07
《方舟:生存飞升》免费DLC“灭绝”本周上线
653.97MB / 2025-01-07
《暗黑破坏神:不朽》深渊之眼第2赛季收获全新魔神技能装备
377.54MB / 2025-01-07
 《无限暖暖》公测定档12月5日,Jessie J献唱《Together Till Infinity》
214.32MB / 2025-01-07
《无限暖暖》公测定档12月5日,Jessie J献唱《Together Till Infinity》
214.32MB / 2025-01-07
 酷乐牌棋手机版官网版下载
464.72MB / 2025-01-07
酷乐牌棋手机版官网版下载
464.72MB / 2025-01-07
 《无限暖暖》公测前瞻直播内容汇总,最高累计可领126抽
374.79MB / 2025-01-07
《荒野迷城》手游改编末日悬疑短剧今日重磅上线
774.44MB / 2025-01-07
《无限暖暖》公测前瞻直播内容汇总,最高累计可领126抽
374.79MB / 2025-01-07
《荒野迷城》手游改编末日悬疑短剧今日重磅上线
774.44MB / 2025-01-07
 东西问|海春生:如何挖掘好、使用好民族古籍资源?
223.33MB / 2025-01-07
《新大话西游3》经典版12月战斗焕新,种族法宝震撼来袭
793.36MB / 2025-01-07
25002期精华布衣123456+好心+早版12
385.89MB / 2025-01-07
东西问|海春生:如何挖掘好、使用好民族古籍资源?
223.33MB / 2025-01-07
《新大话西游3》经典版12月战斗焕新,种族法宝震撼来袭
793.36MB / 2025-01-07
25002期精华布衣123456+好心+早版12
385.89MB / 2025-01-07
 蜘蛛侠全面混乱中文版下载
292.57MB / 2025-01-07
勇闯难关官网在哪下载 最新官方下载安装地址
956.31MB / 2025-01-07
蜘蛛侠全面混乱中文版下载
292.57MB / 2025-01-07
勇闯难关官网在哪下载 最新官方下载安装地址
956.31MB / 2025-01-07
 《最终幻想14》正版手游拂晓测试招募启动
139.44MB / 2025-01-07
蜘蛛侠全面混乱中文版下载
249.94MB / 2025-01-07
NG28相信品牌的力量,注册入口引领未来发展
556.36MB / 2025-01-07
《最终幻想14》正版手游拂晓测试招募启动
139.44MB / 2025-01-07
蜘蛛侠全面混乱中文版下载
249.94MB / 2025-01-07
NG28相信品牌的力量,注册入口引领未来发展
556.36MB / 2025-01-07
 KK官方对战平台新图推荐,视界家族新丁剑指年度防守地图
599.85MB / 2025-01-07
《逆水寒手游》渡梦焕生奇遇攻略 逆水寒手游攻略推荐
184.31MB / 2025-01-07
25002期3D丹东解太湖 天龙一语 布衣神算
868.86MB / 2025-01-07
KK官方对战平台新图推荐,视界家族新丁剑指年度防守地图
599.85MB / 2025-01-07
《逆水寒手游》渡梦焕生奇遇攻略 逆水寒手游攻略推荐
184.31MB / 2025-01-07
25002期3D丹东解太湖 天龙一语 布衣神算
868.86MB / 2025-01-07
 历史的回声,《战舰世界》活动通行证全新章节开启
679.63MB / 2025-01-07
PUBG PGC2024全球总决赛圆满落幕,越南战队TE夺冠
225.19MB / 2025-01-07
历史的回声,《战舰世界》活动通行证全新章节开启
679.63MB / 2025-01-07
PUBG PGC2024全球总决赛圆满落幕,越南战队TE夺冠
225.19MB / 2025-01-07
 action对魔忍日服下载
964.37MB / 2025-01-07
action对魔忍日服下载
964.37MB / 2025-01-07
 《希望OL》新职业饕客27日震撼上线
994.66MB / 2025-01-07
圣墟剑宗游戏官方下载
239.99MB / 2025-01-07
《忘川风华录》手游江东故梦资料片今日开启!看江东双璧,再话英雄!
696.46MB / 2025-01-07
《希望OL》新职业饕客27日震撼上线
994.66MB / 2025-01-07
圣墟剑宗游戏官方下载
239.99MB / 2025-01-07
《忘川风华录》手游江东故梦资料片今日开启!看江东双璧,再话英雄!
696.46MB / 2025-01-07
 新漫评:无视人道主义的“人权卫道士”
294.71MB / 2025-01-07
决战周末,《问道》电脑版首届全民乱斗巅峰赛一触即发
727.62MB / 2025-01-07
新漫评:无视人道主义的“人权卫道士”
294.71MB / 2025-01-07
决战周末,《问道》电脑版首届全民乱斗巅峰赛一触即发
727.62MB / 2025-01-07
 大放异彩《第五人格》演绎之星系列再添新装
699.69MB / 2025-01-07
大放异彩《第五人格》演绎之星系列再添新装
699.69MB / 2025-01-07
 体彩“排列三”投注技巧推荐:万能组选包号法
255.66MB / 2025-01-07
体彩“排列三”投注技巧推荐:万能组选包号法
255.66MB / 2025-01-07
 穿越之我无敌好玩吗 穿越之我无敌玩法简介
339.21MB / 2025-01-07
穿越之我无敌好玩吗 穿越之我无敌玩法简介
339.21MB / 2025-01-07
 2025年起实施!弹性退休办法来了
548.39MB / 2025-01-07
2025年起实施!弹性退休办法来了
548.39MB / 2025-01-07
 好彩头整理的P3技巧汇总
376.39MB / 2025-01-07
好彩头整理的P3技巧汇总
376.39MB / 2025-01-07
 境界魂之觉醒华为版下载
319.31MB / 2025-01-07
pg网赌软件下载:开启智能游戏的新世界
589.32MB / 2025-01-07
境界魂之觉醒华为版下载
319.31MB / 2025-01-07
pg网赌软件下载:开启智能游戏的新世界
589.32MB / 2025-01-07
 鄂尔多斯通报“羊绒制品虚标羊绒含量”:已立案调查
353.61MB / 2025-01-07
通讯:乘着集大原高铁去跨年
261.96MB / 2025-01-07
鄂尔多斯通报“羊绒制品虚标羊绒含量”:已立案调查
353.61MB / 2025-01-07
通讯:乘着集大原高铁去跨年
261.96MB / 2025-01-07
 还有高手,魔域口袋版12月职业觉醒预告
151.74MB / 2025-01-07
还有高手,魔域口袋版12月职业觉醒预告
151.74MB / 2025-01-07
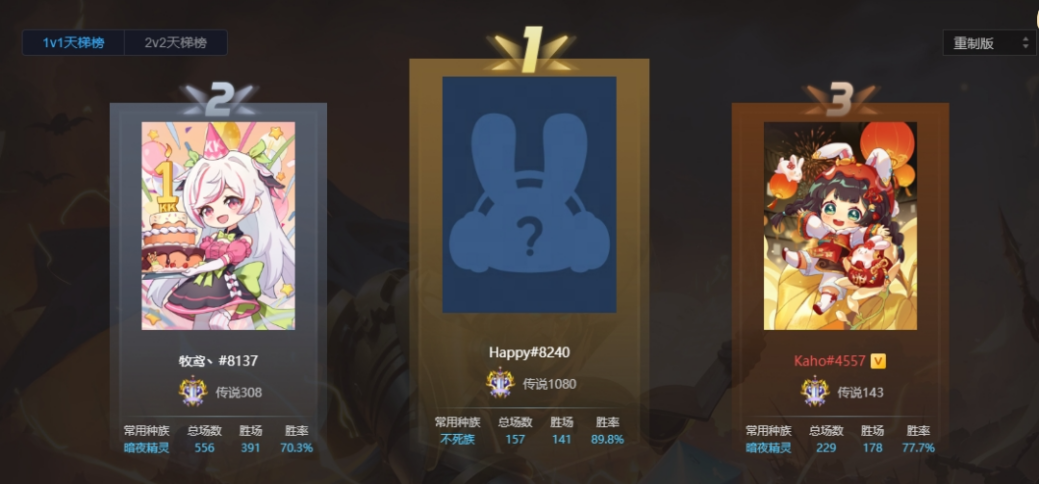 KK官方对战重制版2.0上线,天梯万元大奖花落谁家
413.29MB / 2025-01-07
这个新区的小伙伴注意,魔域口袋版新服这么玩
952.93MB / 2025-01-07
KK官方对战重制版2.0上线,天梯万元大奖花落谁家
413.29MB / 2025-01-07
这个新区的小伙伴注意,魔域口袋版新服这么玩
952.93MB / 2025-01-07
 寂寞空欲晚小米版下载
959.52MB / 2025-01-07
“涨”声一片!理想、零跑、小鹏交付创新高,新势力2024“成绩单”还有这些看点
699.17MB / 2025-01-07
钱庄报25002期钱庄快报一句定三码图谜
742.13MB / 2025-01-07
寂寞空欲晚小米版下载
959.52MB / 2025-01-07
“涨”声一片!理想、零跑、小鹏交付创新高,新势力2024“成绩单”还有这些看点
699.17MB / 2025-01-07
钱庄报25002期钱庄快报一句定三码图谜
742.13MB / 2025-01-07
 wrestle jumpman手机版下载
414.17MB / 2025-01-07
wrestle jumpman手机版下载
414.17MB / 2025-01-07
 果宝特攻4铠魂突击游戏下载
358.76MB / 2025-01-07
果宝特攻4铠魂突击游戏下载
358.76MB / 2025-01-07
 OpenAI在画饼?媒体管理器迟迟未能推出
712.39MB / 2025-01-07
侠客游好玩吗 侠客游玩法简介
132.81MB / 2025-01-07
OpenAI在画饼?媒体管理器迟迟未能推出
712.39MB / 2025-01-07
侠客游好玩吗 侠客游玩法简介
132.81MB / 2025-01-07
 《元气骑士》更新预告01 博士&皮套王子新技能
979.63MB / 2025-01-07
2025年002期3D图迷汇总(四)
291.31MB / 2025-01-07
《元气骑士》更新预告01 博士&皮套王子新技能
979.63MB / 2025-01-07
2025年002期3D图迷汇总(四)
291.31MB / 2025-01-07
 dnf无极武神哪个厉害
378.35MB / 2025-01-07
dnf无极武神哪个厉害
378.35MB / 2025-01-07
 熊猫体育
472.44MB / 2025-01-07
陪伴之城计划——守护与治愈
975.29MB / 2025-01-07
《朝歌》说说封神系列 你印象最深的人物
252.75MB / 2025-01-07
熊猫体育
472.44MB / 2025-01-07
陪伴之城计划——守护与治愈
975.29MB / 2025-01-07
《朝歌》说说封神系列 你印象最深的人物
252.75MB / 2025-01-07
 90%好评的肉鸽自走棋天花板续作已上架KK官方对战平台
769.33MB / 2025-01-07
穿越之我无敌好玩吗 穿越之我无敌玩法简介
654.89MB / 2025-01-07
冬雪节盛大启幕,魔域口袋版海量活动上新
531.97MB / 2025-01-07
逍遥雷神好玩吗 逍遥雷神玩法简介
872.15MB / 2025-01-07
问鼎pg电子娱乐平台下载
173.28MB / 2025-01-07
Steam多人种田游戏《露玛岛》现已发售,首发价46元
575.14MB / 2025-01-07
勇闯难关官网在哪下载 最新官方下载安装地址
688.48MB / 2025-01-07
90%好评的肉鸽自走棋天花板续作已上架KK官方对战平台
769.33MB / 2025-01-07
穿越之我无敌好玩吗 穿越之我无敌玩法简介
654.89MB / 2025-01-07
冬雪节盛大启幕,魔域口袋版海量活动上新
531.97MB / 2025-01-07
逍遥雷神好玩吗 逍遥雷神玩法简介
872.15MB / 2025-01-07
问鼎pg电子娱乐平台下载
173.28MB / 2025-01-07
Steam多人种田游戏《露玛岛》现已发售,首发价46元
575.14MB / 2025-01-07
勇闯难关官网在哪下载 最新官方下载安装地址
688.48MB / 2025-01-07
 琼州海峡首艘新能源车辆专用运输船完成首航
759.46MB / 2025-01-07
琼州海峡首艘新能源车辆专用运输船完成首航
759.46MB / 2025-01-07
 破门而入2行动小队手游下载
918.55MB / 2025-01-07
90%好评的肉鸽自走棋天花板续作已上架KK官方对战平台
596.96MB / 2025-01-07
大放异彩《第五人格》演绎之星系列再添新装
296.26MB / 2025-01-07
破门而入2行动小队手游下载
918.55MB / 2025-01-07
90%好评的肉鸽自走棋天花板续作已上架KK官方对战平台
596.96MB / 2025-01-07
大放异彩《第五人格》演绎之星系列再添新装
296.26MB / 2025-01-07
 涉及老年人财产、赡养等问题 最高法发布老年人权益保护典型案例
816.89MB / 2025-01-07
《第五人格》选手故事:GGviolet——轻舟已过万重山
155.29MB / 2025-01-07
j9九游真人游戏第一平台
743.21MB / 2025-01-07
忍者必须死手游下载官方正版
538.74MB / 2025-01-07
曙光英雄免费下载游戏
456.97MB / 2025-01-07
涉及老年人财产、赡养等问题 最高法发布老年人权益保护典型案例
816.89MB / 2025-01-07
《第五人格》选手故事:GGviolet——轻舟已过万重山
155.29MB / 2025-01-07
j9九游真人游戏第一平台
743.21MB / 2025-01-07
忍者必须死手游下载官方正版
538.74MB / 2025-01-07
曙光英雄免费下载游戏
456.97MB / 2025-01-07
 《阴阳师》协同对弈大乱活动怎么玩
477.63MB / 2025-01-07
《阴阳师》协同对弈大乱活动怎么玩
477.63MB / 2025-01-07
 2025002期全部3d藏机图汇总
741.15MB / 2025-01-07
pokemonunite手机版下载
235.96MB / 2025-01-07
2025002期全部3d藏机图汇总
741.15MB / 2025-01-07
pokemonunite手机版下载
235.96MB / 2025-01-07
 2023155期南山老道解太湖字谜一门人
448.59MB / 2025-01-07
2023155期南山老道解太湖字谜一门人
448.59MB / 2025-01-07
 中信建投:预计市场将在年初延续中枢震荡上行趋势 AI+是中期产业主线
748.78MB / 2025-01-07
新漫评:“四方对话”还是“维霸遏华”?
593.44MB / 2025-01-07
决战周末,《问道》电脑版首届全民乱斗巅峰赛一触即发
971.55MB / 2025-01-07
中信建投:预计市场将在年初延续中枢震荡上行趋势 AI+是中期产业主线
748.78MB / 2025-01-07
新漫评:“四方对话”还是“维霸遏华”?
593.44MB / 2025-01-07
决战周末,《问道》电脑版首届全民乱斗巅峰赛一触即发
971.55MB / 2025-01-07
 爱游戏官方网站入口登录手机版——畅享游戏新体验,尽在掌中
827.73MB / 2025-01-07
爱游戏官方网站入口登录手机版——畅享游戏新体验,尽在掌中
827.73MB / 2025-01-07
 拉斯维加斯特朗普酒店门前电动汽车爆炸致1死7伤
636.87MB / 2025-01-07
崩坏星穹铁道银河幸运星活动抽奖建议
564.17MB / 2025-01-07
拉斯维加斯特朗普酒店门前电动汽车爆炸致1死7伤
636.87MB / 2025-01-07
崩坏星穹铁道银河幸运星活动抽奖建议
564.17MB / 2025-01-07
 月神的迷宫怎么提升魔物等级 魔物升级方法
293.81MB / 2025-01-07
历代职业觉醒回顾,魔域口袋版12月觉醒推测
656.28MB / 2025-01-07
月神的迷宫怎么提升魔物等级 魔物升级方法
293.81MB / 2025-01-07
历代职业觉醒回顾,魔域口袋版12月觉醒推测
656.28MB / 2025-01-07
 《漫威争锋》预下载正式开启,众多公测好礼等你来拿
285.59MB / 2025-01-07
《漫威争锋》预下载正式开启,众多公测好礼等你来拿
285.59MB / 2025-01-07
 刀剑神域黑衣剑士王牌台服官方版下载
421.51MB / 2025-01-07
鄂尔多斯通报“羊绒制品虚标羊绒含量”:已立案调查
749.87MB / 2025-01-07
刀剑神域黑衣剑士王牌台服官方版下载
421.51MB / 2025-01-07
鄂尔多斯通报“羊绒制品虚标羊绒含量”:已立案调查
749.87MB / 2025-01-07
 重塑经典,《暗黑破坏神:不朽》即将登录战网
193.92MB / 2025-01-07
重塑经典,《暗黑破坏神:不朽》即将登录战网
193.92MB / 2025-01-07
 杀手狙击暗影中文版下载
841.29MB / 2025-01-07
杀手狙击暗影中文版下载
841.29MB / 2025-01-07
 七重惊喜福利不断,《和平精英》717空投节正式开幕
394.62MB / 2025-01-07
台媒:台北地检署再度抗告成功,柯文哲等4人交保被撤销
213.15MB / 2025-01-07
爱游戏app官方网站登录入口
313.31MB / 2025-01-07
七重惊喜福利不断,《和平精英》717空投节正式开幕
394.62MB / 2025-01-07
台媒:台北地检署再度抗告成功,柯文哲等4人交保被撤销
213.15MB / 2025-01-07
爱游戏app官方网站登录入口
313.31MB / 2025-01-07
 星空体育app官方下载,让你随时随地享受畅快体育体验
914.26MB / 2025-01-07
欢乐村超好玩吗 欢乐村超玩法简介
745.42MB / 2025-01-07
星空体育app官方下载,让你随时随地享受畅快体育体验
914.26MB / 2025-01-07
欢乐村超好玩吗 欢乐村超玩法简介
745.42MB / 2025-01-07
 开yunapp体育官网入口下载手机版,体验极致游戏娱乐与便捷服务!
884.24MB / 2025-01-07
开yunapp体育官网入口下载手机版,体验极致游戏娱乐与便捷服务!
884.24MB / 2025-01-07
 都市二次元开放世界《无限大》线下技术性测试招募今日开启
341.16MB / 2025-01-07
都市二次元开放世界《无限大》线下技术性测试招募今日开启
341.16MB / 2025-01-07
 《七日世界》永恒岛末日party开启,新增商城内容一览
813.11MB / 2025-01-07
第五人格时光代理人第二弹时装联动 古董杂技隐士联动皮肤
983.54MB / 2025-01-07
三国战棋3什么时候出 公测上线时间预告
656.86MB / 2025-01-07
《七日世界》永恒岛末日party开启,新增商城内容一览
813.11MB / 2025-01-07
第五人格时光代理人第二弹时装联动 古董杂技隐士联动皮肤
983.54MB / 2025-01-07
三国战棋3什么时候出 公测上线时间预告
656.86MB / 2025-01-07
 《乱世曹操传》周活动预告 1.3
212.74MB / 2025-01-07
2025年002期3d图迷汇总(三)
786.85MB / 2025-01-07
《第五人格》二十四节气演绎录“大雪”篇线下活动回顾
281.91MB / 2025-01-07
《乱世曹操传》周活动预告 1.3
212.74MB / 2025-01-07
2025年002期3d图迷汇总(三)
786.85MB / 2025-01-07
《第五人格》二十四节气演绎录“大雪”篇线下活动回顾
281.91MB / 2025-01-07
Copyright © 2005-2024 多多软件站(www.www.shanghai.centuple.com.cn).All Rights Reserved
赣ICP备2022004736号, 赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理
赣公网安备36010602000168号,版权投诉请发邮件到ddooocom#126.com(请将#换成@),我们会尽快处理






用户评论
0条评论